
On AI Infrastructure in Biology
Three stories; six parameters

Welcome to The Century of Biology! This newsletter explores data, companies, and ideas from the frontier of biology. You can subscribe for free to have the next post delivered to your inbox:
Today, we’re going to consider why it might now be possible to build big AI infrastructure businesses in biology.
Enjoy! 🧬

Mike Tyson famously said that “everyone has a plan until they get punched in the face.” As the COVID bubble burst, we learned that “every biotech has a plan until the market collapses.”

The pandemic spurred enormous enthusiasm for biotech investment. Stocks soared and many new companies were listed. I’m not going to belabor the point, but this catalyst was temporary. High-flying companies found themselves in a world of hurt.
We are still living through the aftermath right now. While the S&P 500 has more than doubled over the past five years, the XBI has failed to fully regain its value over the same time frame.
But the biotech industry has fundamentals on its side. Patent cliffs are still looming and the world’s armamentarium is still far from complete. Nothing about the current market cycle changes the fact that we are living through a renaissance in biology and technology. Our tools for understanding and engineering life are compounding.
And few industries offer a more direct way to produce financial returns by advancing scientific and human progress. In other words, it’s still a beautiful way of doing well by doing good.
Investors had to figure out how to get back on the horse. The return of capital to the sector happened in fits and starts. In 2023, there was a big contraction in investment relative to the hyperactive cycle of 2020-2022. Less deals happened.
When dealmaking returned, it happened unevenly. In 2024, we saw a spree of $100M+ “mega-rounds” happen. Large syndicates formed to insulate companies from market volatility. Basically, a small set of anointed companies raised a lot of money. Investors seemingly sought safety in numbers.
Many of these bets reflected viewpoints on where the next big blockbuster will be. Immunology, neuroscience, and oncology were major focus areas. Next-generation modalities like in vivo cell therapies and T-cell engagers were also palatable.
Another major theme—which is also one of the major themes of this newsletter—has been AI for biotech. Massive new investments are being made.
In April of 2024, we saw a $1B “Seed” round go to Xaira, a business aiming to reimagine many layers of drug discovery R&D with AI. This was one of the largest initial financings in the history of our industry.
Xaira was not alone. In June of 2024, Formation Bio raised $372M for their own thesis on accelerating biotech with AI. In March of this year, Isomorphic Labs raised $600M to continue scaffolding a new pharma organization around the research lab that produced the AlphaFold breakthrough.
As an early-stage investor, part of my job involves talking to a lot of different people across academia, biotech, and pharma. Broadly speaking, people don’t find these investments that crazy. We’ve been desensitized to mega-rounds over the years. Drug discovery is expensive! And it’s becoming consensus that AI will play a meaningful role in the future of biotech R&D.
But another set of deals is drawing more initial skepticism. Businesses such as EvolutionaryScale, Chai Discovery, Cradle Bio, Achira, Latent Labs, and Axiom have also recently raised large sums of capital to build AI solutions for biotech. A major difference between this set of companies and the likes of Xaira, Formation, and Isomorphic is that they seem to be pursuing value creation by selling technology rather than drugs.
This triggers strong reactions. Schrödinger is constantly cited as an example of how hard this business model is. After 35 years in business selling some of the leading drug discovery software solutions, their market cap is ~$1.5B. This is nothing to sneeze at, but it pales in comparison to the value created from single drugs developed using their technology, such as the sale of Nimbus’s TYK2 program for more than $4B.
The overarching sentiment is that drugs create far more value than discovery tools and that nothing about AI will change that. If you have a great new discovery technology, the most logical thing to do is to use it to make new drugs. The subtext is, “What are all these founders and investors thinking?!”
There is a kernel of truth to this. I spend a lot of my time searching for new platform companies with technologies that can make otherwise impossible drugs. One of the evaluation criteria for AI in biotech should be whether it leads to the development of fantastic new medicines that improve the human condition.1
But I don’t think that means there can’t be massive, objectively investable infrastructure businesses that create a lot of value for the industry. In tech, it’s completely obvious that infrastructure businesses providing tools rather than end products can be huge. Consider Datadog, a >$50B public company that provides cloud observability solutions—in other words, infrastructure for managing your infrastructure.
The most extreme example is NVIDIA. The biggest company in the history of the world is an infrastructure provider.
So, how might AI infrastructure companies actually create and capture value in biotech?
To explore this, I want to tell you three possible stories about the technological and structural evolution of our industry. Each story has parameters, which are numerical placeholders whose values you can personally estimate based on your own beliefs about the future.
Compute as a Reagent
Twenty five years ago, the biotech industry spent exactly $0 on high-throughput DNA and RNA sequencing. That’s an obvious statement because the technology hadn’t been invented yet. And it certainly hadn’t dramatically decreased in cost.
Last year, Illumina, the largest next-generation sequencing (NGS) company, generated $4.4B in revenue.
Factoring in the rest of the players in the market, the total annual spend on NGS is around ~$10B—which is the number most of the market research firms converge on.2
How did this happen? What drove the increase from $0 to ~$10B?
First, NGS became a ubiquitous tool in the life sciences research market. Illumina describes this market by saying, “This includes laboratories associated with universities, research centers, and government institutions, along with biotechnology and pharmaceutical companies.”
Labs around the world were able to answer new questions. Initially, researchers used NGS to sequence and compare genomes. Use cases evolved. As functional genomics emerged, massive gene expression experiments became drivers of continued growth and adoption. In 2022, we saw the first genome-wide CRISPR perturbation experiment, which involved sequencing over two million single cells.
This scale of experiment—let alone the CRISPR technology—would be basically unimaginable to scientists even a decade ago. The crucial point is, as NGS declined in cost, it proved to be elastic, meaning that scientists kept figuring out ways to use even more of it.
In addition to the research market, NGS is now used in the clinic. Two of the largest clinical uses are noninvasive prenatal testing (NIPT) and cancer screening (both for diagnostics and prognostics to help predict treatment responses and guide care). These are both valuable applications with huge markets that are projected to keep growing.
Rare disease diagnosis and infectious disease monitoring are also big drivers of clinical NGS growth. And just like the growth of the research market, it seems likely that we’ll keep discovering new clinical applications of sequencing. For example, T-cell receptor and B-cell repertoire sequencing could become an integral part of autoimmune diagnosis in the future.
It’s worth noting what NGS didn’t do. Despite the optimism around deciphering “the genetic blueprint for human beings,” as President Clinton stated, genomics didn’t solve biology. And it didn’t solve drug discovery or disease diagnosis.
But it did prove to be a foundational technology that justified converting a growing amount of capital into biological information. NGS was a technological breakthrough for biology. It continues to deliver real value to researchers and clinicians around the world.
The NGS market has consistently sustained a double digit (~11%) compound annual growth rate and doesn’t seem to be slowing down.3 It’s not absurd to imagine the market growing to >$30B over the next decade.
So, that’s value creation. What about value capture?
The primary way that NGS companies make money is by selling consumables—which are the reagents and materials needed for an experiment—at a healthy margin. In 2024, Illumina made 12% of their revenue from selling instruments and 72% of their revenue from consumables.4 The gross margins on their core business were 67.1%.
As NGS became a ubiquitous technology, people built businesses on top of it. For example, 10X Genomics sells instruments and consumables to prepare samples for single-cell sequencing experiments. In 2024, they generated $610M of revenue, with $493M of that coming from consumables.
Clinical NGS companies make money by selling tests. Some of these businesses are growing very quickly. In 2022, Natera generated ~$800M in revenue. By 2024, this had more than doubled to ~$1.7B, with gross margins increasing from 44.4% to 60.3% in the same time period.
Interestingly, because clinical NGS is growing so quickly, Natera is now a bigger company than Illumina—who is the provider of the actual underlying sequencing technology! As of writing, Natera’s market cap is ~$31B and Illumina’s is ~$18B.5
What Powers give these businesses the ability to command such strong margins?
I’ve already taken a crack at trying to explain this for Illumina. In large part, the primary Powers are two-fold. They have Cornered Resources in the form of a complex thicket of patents protecting their proprietary sequencing chemistry. Illumina also emerged as a definitive research standard, which introduced Switching Costs as well as Network Economies. People benefit from having the sequencing machine that most assay and software developers are developing new solutions for.
Similarly, Natera has their own IP portfolio for their tests. There is likely also the benefit of being an early mover to gain reimbursement and adoption by clinicians. But Natera will have to continue to fend off competitors, including Illumina and BillionToOne, who just had a fantastic IPO.
So, what does any of this have to do with AI?
Just as NGS rapidly permeated the research market, scientists around the world are integrating new AI tools into their work. Arguably, the adoption is happening faster and is more widespread.
And just as NGS led to growth in spend on chemistry reagents, AI is driving growth for another type of research reagent: compute.
Taken together, these two facts could lead to greater research productivity and the growth of large businesses.
Let’s make this more concrete.
Google Deepmind released AlphaFold 2, which was the tipping point for protein structure prediction, in November of 2020. In July of the following year, they launched the AlphaFold Protein Structure Database in collaboration with the European Bioinformatics Institute. In just over four years, DeepMind says the database “has over two million users in 190 countries.”
Think about that number for a second. How many biologists even are there in the world? In 2021, UNESCO estimated there were 8.854 million researchers worldwide, inclusive of every scientific discipline. Let’s assume somewhere between 20-30% of those researchers are doing something related to biology. That’s somewhere between 1.8 million and 2.6 million researchers.
That would mean that in less than five years, we went from basically no biologists using AI structure prediction models to basically every biologist using them.
This squares with my subjective experience. I don’t know any researchers who aren’t at least playing around with these types of databases and doing basic searches.
To be clear, this type of usage represents a small fraction of any given research project. My former PhD advisor Michael Fischbach has a good framework for thinking about this type of tool. In his course on problem choice and decision trees in science and engineering, he compares and contrasts how widely used a tool is versus the criticality of a tool for a given experiment.
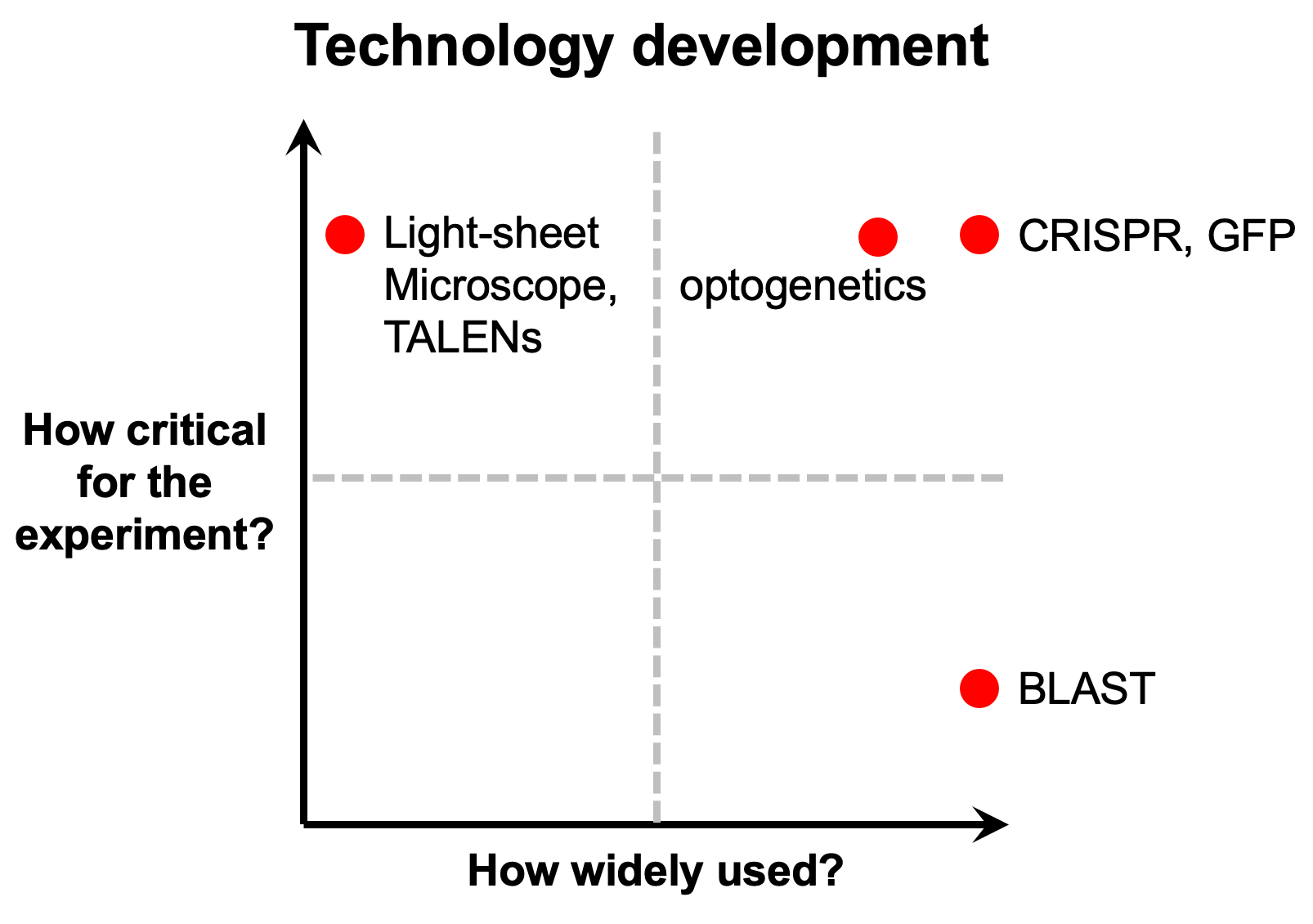
Some tools, like complex and expensive microscopes, can be used to answer certain research questions all on their own. But their use is limited to a small number of specialist labs. Other tools, like CRISPR, are equivalently powerful, but much more widely adopted. Others, like the BLAST software program, are very widely used but are not as mission critical.
The AlphaFold Protein Structure Database resembles BLAST. This is just one example of this type of ambient AI usage for biology.
Consider this anecdote from a recent article on Amgen’s approach to AI adoption:
Traditionally, Amgen’s scientists would manufacture a few hundred milligrams of any protein of interest to assess viscosity. Today, Amgen runs an algorithm predicting viscosity from the sequence of a protein, before it’s ever made in the lab. If the prediction is not promising, it’s not made.
“We now do it every day on every molecule,” said Alan Russell, head of R&D technology and innovation at Amgen. “There are literally 20 or 30 other predictive models that we use to correct all of the therapeutic molecular attributes that could cause a problem.”
Like NGS, these types of models aren’t solving biology. But they are delivering sufficient value to justify converting a growing amount of capital into biological information.
It also seems like these models can serve as mission critical tools for research projects just like microscopy or CRISPR.
Last year, I read an interesting research paper about the possible evolutionary trajectories of the SARS-CoV-2 virus. The primary goal was to better understand how the virus’s spike protein might mutate and change over time.
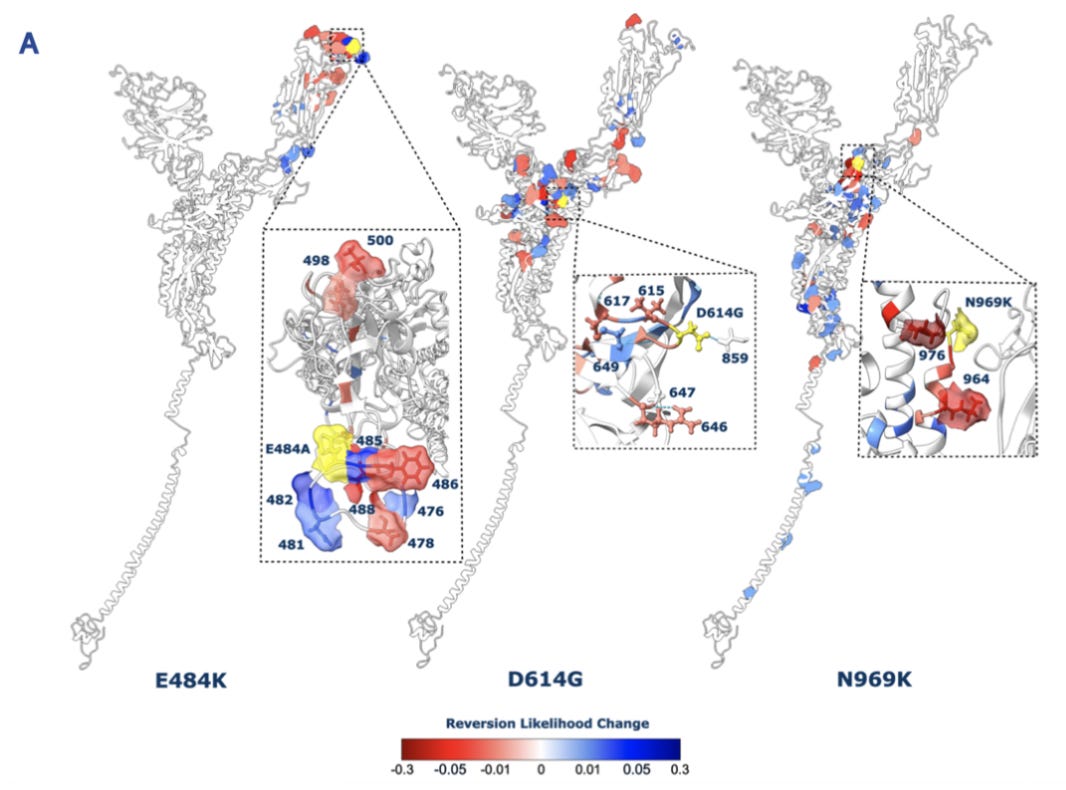
In the first version of the preprint that was posted, they performed a comprehensive deep mutational scanning experiment of the protein sequence. They also ran some experiments to assess epistasis and look for signals of evolutionary selection.
But none of these experiments were done in the lab. Instead, they were all in silico experiments carried out using a protein language model (pLM). Using a single protein sequence, a pLM, and a little bit of existing experimental data, this group produced a novel research paper.6
Of course, computational biologists publish “dry” papers with no experiments in journals every day. But this type of project felt like a glimpse into a world where these models are used as a new form of experimental apparatus.
If model progress paused today, we would still have years worth of fruitful interpretability research to tease out new biology from what these models have already learned.
Considering both the ambient usage of AI in biology and its use as a new form of experimental tool, we should expect greater conversion of capital into biological information via compute over time.
There are some leading indicators of this being true. Lilly recently announced they are building a giant supercomputer with NVIDIA. Several other pharmaceutical companies including Novo Nordisk, GSK, and AstraZeneca have already invested in similar compute buildouts.
This introduces an interesting question: will other businesses capture any of this value besides NVIDIA?
In Illumina’s case, they owned the proprietary chemistry reagent. Here, NVIDIA owns the compute reagent.
I think the answer is yes. In tech, people talk about “platform shifts,” where a new foundational technology enables all sorts of new applications and businesses. For example, cloud and mobile were both big platform shifts. It sure seems like AI is the next big platform shift.
In this type of transition, it’s incredibly hard for one platform company to offer every solution needed to build the next wave of applications. AWS doesn’t ship everything that developers need to make full use of the cloud. There are tons of massive companies that command healthy margins by solving hard infrastructure problems on top of this underlying platform. I happen to work at Amplify, which is a firm that has done phenomenally well investing in these types of infrastructure businesses.
Joe Lonsdale recently wrote a nice piece on the different layers of opportunities within the AI stack being built out.7
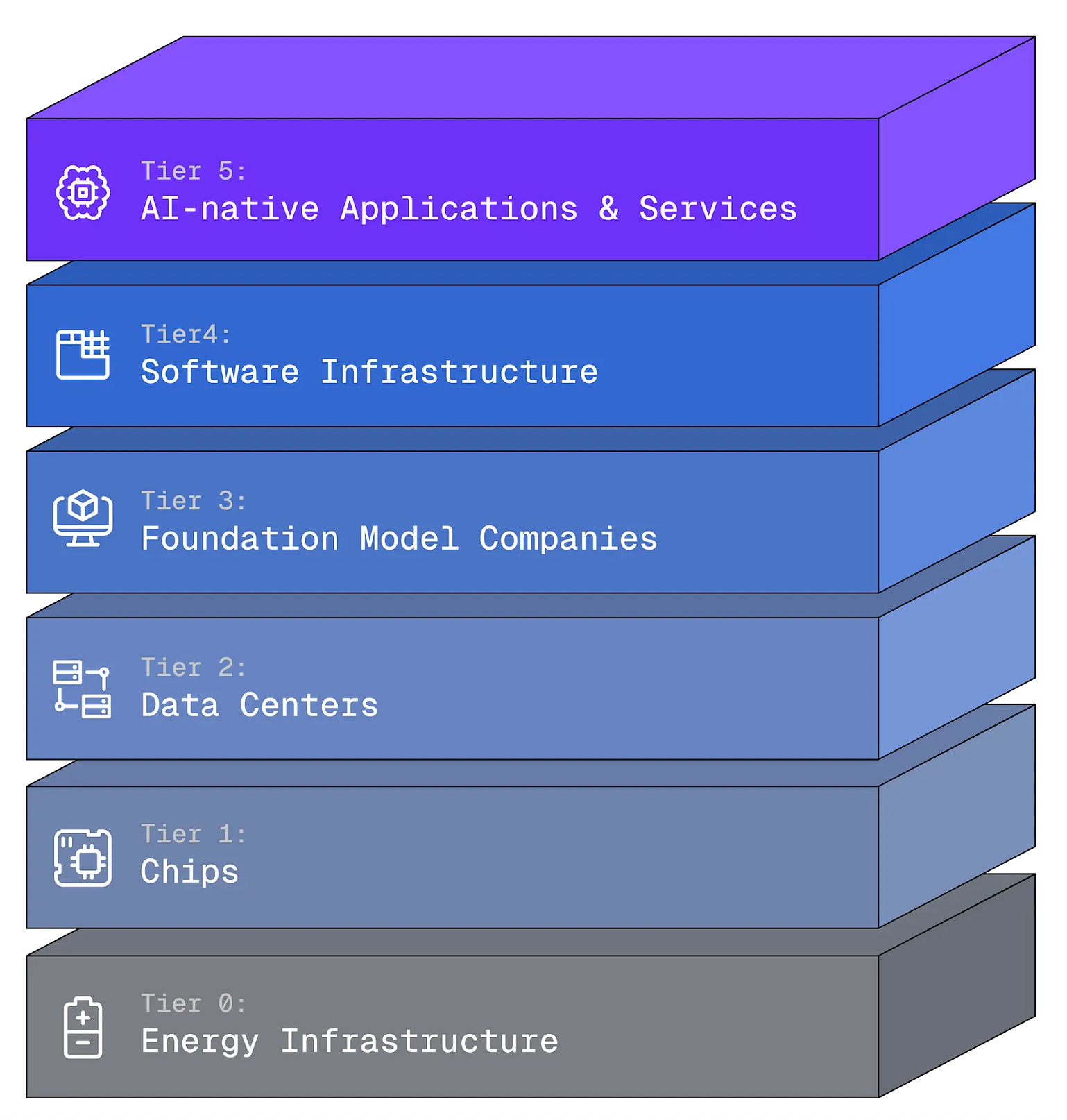
We’re seeing pharmaceutical companies invest heavily in chips, which means there could be a growing life science enterprise market for solutions higher up in the stack.
Beyond the enterprise, I think we could be dramatically under-calling the size of the broader life sciences research market across smaller labs, institutions, and startups around the world. Just like NGS, it seems like researchers will keep figuring out new ways to use these tools to address all sorts of biological problems—especially as costs keep coming down.
There are also clinical use cases for AI. For example, a wave of “digital oncology” companies like Artera and Valar Labs are popping up. Their goal is to use AI to create new biomarkers from existing clinical data—such as pathology slides—to help guide cancer care. Over time, these models could compete head-to-head with clinical NGS offerings.
Now let’s turn this story into a concrete prediction like forecasters love to do.
Ten years from now, $X billion will be spent on AI compute in biology, and Y% of that spend will be captured by new startups.
You pick the parameters. When doing so, it’s worth having a bit of humility. Bets on market creation are often non-obvious. When Uber got started, many people passed on investing because the taxi market didn’t seem that big. This missed the fact that the mobile ride share market was much bigger. Predicting the future is hard.
“From the Wet Lab to the GPU Cluster”
What is AI, really?
Let’s peel back one layer of the onion and instead ask: what is deep learning? This is the set of algorithmic techniques that is now synonymous with modern AI.
Deep learning methods are fundamentally concerned with approximating functions. At the highest level, a function is a process that maps a set of inputs to a set of outputs. Lots of processes, like applying a label to an image, translating text between languages, or folding an amino acid sequence into a 3D protein structure can be described using the language of functions.
Deep learning has been incredibly successful at solving these types of problems. As Michal Bronstein, a prolific deep learning researcher, has previously argued, much of this success boils down to two core principles:
“The notion of representation or feature learning, whereby adapted, often hierarchical, features capture the appropriate notion of regularity for each task”
“Learning by gradient descent-type optimization, typically implemented as back-propagation.”
Deep learning provides a set of architectures, which are computational primitives for detecting the key features of an input that dictate what the corresponding output will be when it is passed through a function.
Next, optimization algorithms like back-propagation make it possible to learn approximations of a function from data.
Let’s consider a concrete example. In the early days of computer vision, a specific architecture called a convolutional neural network made it possible to extract the hierarchical features in an image that were predictive of what the correct label was. This type of mapping is then optimized with massive amounts of image data using the back-propagation algorithm—meaning the neural network is constantly tuned to have higher accuracy.

Bronstein had another key insight about what led to the success of deep learning. He wrote, “While learning generic functions in high dimensions is a cursed estimation problem, most tasks of interest are not generic and come with essential predefined regularities arising from the underlying low-dimensionality and structure of the physical world.”
Basically, many complex functions seem impossible to learn. But it turns out that they aren’t. AI can learn them. This is because the physical world actually has a simpler underlying structure that can be learned. This is why science works in the first place.
Physicists have had a lot of success in deriving some of these functions with lots of math and mental horse power. But other functions have resisted a similar treatment. Deep learning offers a set of tools for learning these thornier functions from data.
Let’s turn this general intuition towards the question of AI’s utility in biology.
Biology is chock full of problems that have resisted mathematical description. It’s incredibly hard to figure out the underlying function that dictates how an amino acid sequence will fold into a protein structure, what drives the differentiation from one cell type to another, or why some patients respond to specific drugs and others don’t.
But we can collect data by performing experiments. There are dozens of experimental techniques for resolving a protein’s structure. For decades, researchers around the world deposited structural data into the Protein Data Bank. Google DeepMind trained the AlphaFold models using this data.
So in a very real sense, the function AlphaFold is approximating is an experiment. It’s computationally deriving what we would otherwise measure in the physical world.
Right now, structure prediction models still have lower accuracy and resolution than physical experiments. The major difference is in speed, cost, and complexity. Producing a crystal structure is very hard, but basically any scientist can now ask structural questions as part of their project at the speed of inference.
Now let’s take this to its logical extreme. Given the rate of progress in molecular machine learning, is it possible that AI surpasses experimental accuracy?
It seems possible. Researchers have already made the argument that AlphaFold 2 predictions “are usually more accurate” than structures produced using nuclear magnetic resonance (NMR) techniques. That’s pretty crazy.
Compared to experiments, AI models have a few advantages:
They can average out background experimental noise,
incorporate priors from massive data sets like the PDB, and
interpolate between nearby data points.
Assume we keep figuring out clever representations (like CNNs for images) for these problems. And we keep pouring more high-quality data into these models. Could inference be more accurate than measurement?
Already, for proteins without existing structures, “the use of AlphaFold models in structure-determination protocols has been shown to reduce the time and effort required relative to ab initio model building.” The starting point is a computational prediction, which can then be refined with a smaller set of experimental data points.

Scientists used to generate data and then fit models. Now, in many cases, scientists are using models to generate predictions and then refine them with data. This is an interesting inversion.
In our first story, we compared AI models to the rise of NGS. The idea was that AI can be thought of as a new form of information generation whose usage will grow. This is a story of category creation.
Here, the idea is that AI can potentially replace existing experiments.
Consider Amgen’s AI usage again:
Traditionally, Amgen’s scientists would manufacture a few hundred milligrams of any protein of interest to assess viscosity. Today, Amgen runs an algorithm predicting viscosity from the sequence of a protein, before it’s ever made in the lab. If the prediction is not promising, it’s not made.
They are predicting the outcome of an experiment before they do it. I’m assuming they have amassed a lot of this data running R&D at Amgen over the last 35 years. Seemingly, enough data to learn an approximation of the mapping between a protein’s sequence and this physical property. And they have enough confidence in this approximation to let it determine what experiments they do.
At that point, the actual physical experiment becomes a verification step. Until verification, R&D can move at the speed of inference. More ideas can be tested.
Let’s consider another example.
Recently, I wrote about the growth in research on “virtual cell” models. For decades, researchers have attempted to build computational models of cells. But right now, this term is mainly being used to describe a very specific thing.
The main thrust of virtual cell research is predicting single-cell perturbations.
As NGS scaled, it became possible to measure gene expression in millions of individual cells.8 With the advent of CRISPR and improvements in DNA synthesis, our ability to perturb—basically, poke or manipulate—the genetics of individual cells also scaled dramatically.
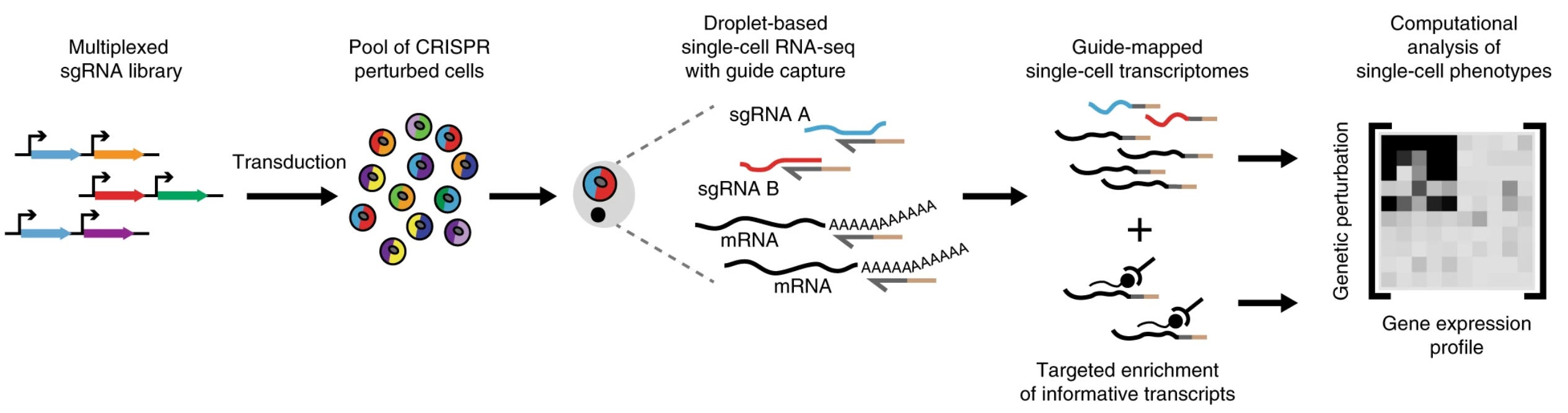
The Arc Institute’s Virtual Cell Challenge is centered around predicting the result of this type of experiment. Using the massive data sets that have been generated using these types of technologies, the goal is to predict things like the gene expression profile in response to a new perturbation.9
Again, predicting experiments. At the moment, these virtual cell models are far less performant than protein models. But they may already be surprisingly close to replacing some experiments.
This is because the number of possible experiments is massive. In a 2023 talk on AI for drug discovery, Aviv Regev said, “When you talk about new medicines, the numbers become really, really big.”

There are roughly 20,000 genes in the human genome, meaning there are around ten trillion possible gene combinations to consider.10 The human body has thousands of different cell types, each of which can adopt different states in response to signals. We can’t possibly test all of these combinations and states in the lab.
For some of the leading researchers working on virtual cells, the goal is simply to make a model that is good enough that researchers start testing ideas in silico before proceeding with experiments. This would make it possible to run much larger digital experiments before doing smaller sets of physical experiments.
If these models get much better, there is a chance the ratio of digital and physical experiments could change dramatically. Stephen Quake envisions a future where “cell biology goes from being 90% experimental and 10% computational to the other way around.” Imagine a world where the next Yamanaka factors are discovered computationally.
Ron Alfa, the CEO of Noetik, described this shift by saying, “We’re moving biology from the wet lab to the gpu cluster.”
Now let’s return to our earlier logic for value creation and value capture.
The global pharma industry spends ~$250B annually on R&D in pursuit of new medicines. Historically, this research happened inside of Big Pharma companies. But as the industry matured, they divested more of this work to external organizations.
And smaller biotechs, who now collectively represent a large fraction of early-stage R&D, also benefit from outsourcing portions of their work instead of setting up every single assay from scratch internally.
These external organizations are called contract research organizations (CROs) and contract development and manufacturing organizations (CDMOs). Outsourced R&D spend that goes to CROs and CDMOs is growing faster than internal R&D spend.
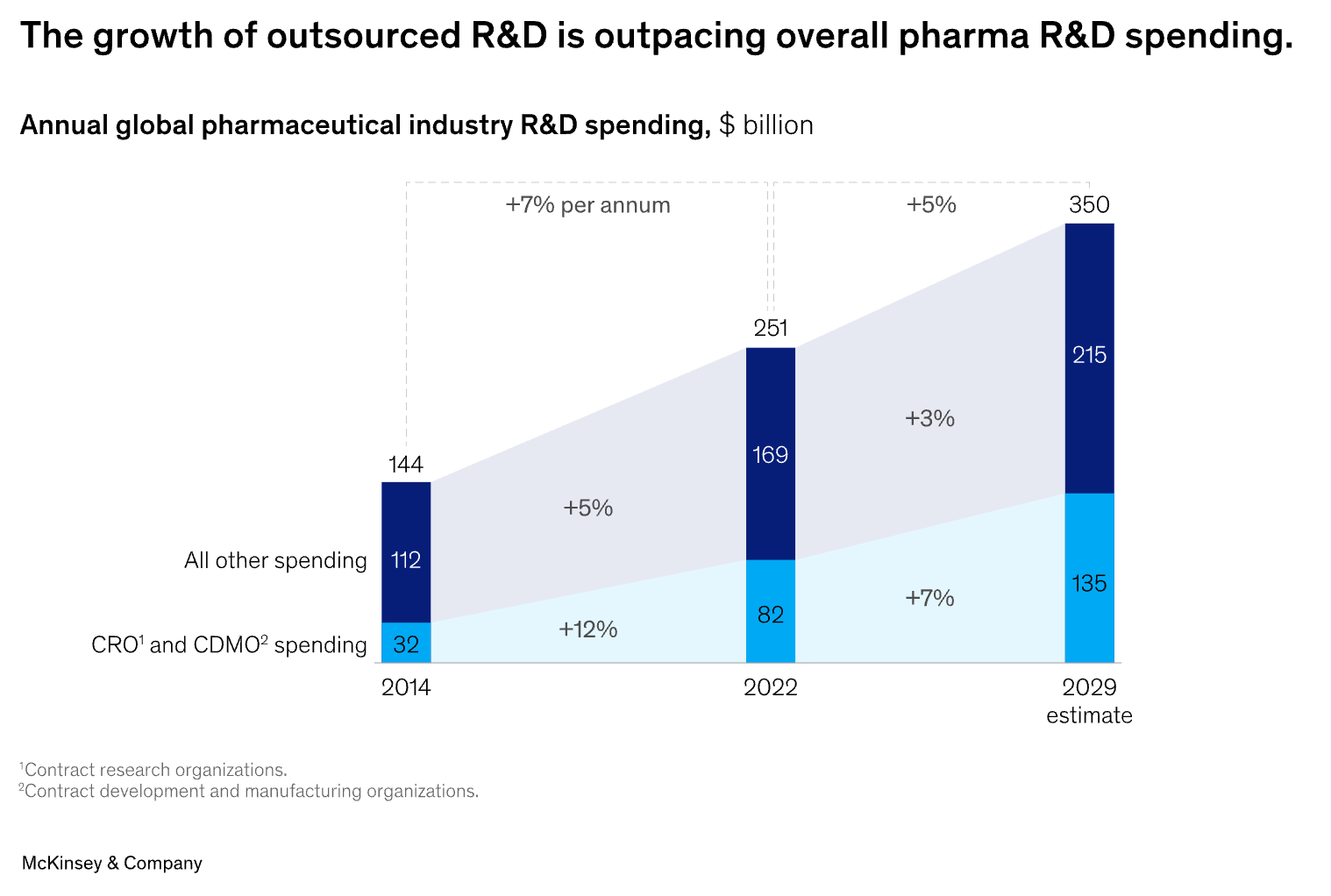
Assume roughly a third of the outsourced R&D spend goes to CROs. That’s ~$30B annually. How much of that will ultimately go to computational experiments instead of lab experiments?
Imagine a CRO that offers what Amgen already does internally as a product. They provide a suite of tools for computational drug design and ~20-30 (or more) different experimental simulators to test the designs. Maybe they even experimentally verify the final predictions with a robotic lab or a passthrough contract to an experimental CRO.
This doesn’t seem that far-fetched. Just like NGS, there could be elasticity. If a computational experiment was a tenth the price, my bet is that researchers would find ten times the number of experiments to do—or more.
This would help alleviate the bottleneck of physical experimentation on a researcher’s creativity.
The global R&D market is already really big. The main question is if new AI companies will be able to scale and compete for a bigger slice of the pie over time.
Framing it as a prediction:
Ten years from now, X% of experiments in the R&D market will be computational, and Y% of those experiments will be run by new startups.
If this shift happens, there will be another big question. What will drive pricing power between companies in this market? In other words, why won’t it be a race to the bottom?
This could come from differentiated model research, sticky workflows and integrations, or simply access to compute. But time will tell. First, we’ll need to see scientists shift more work from the bench to the cluster.
AI for Program Decisions
I distinctly remember the first time I met Brandon White. At the time, he was the Head of Product at Spring Discovery, a startup selling AI-powered image analysis tools into pharma. He was trying to poach me from Stanford to come work as an engineer there.
We met at Verve Coffee Roasters on University Avenue in Palo Alto, right off of campus. I was there early, so I grabbed a coffee and sat down. A few minutes later, Brandon strode in wearing a crisp pair of sneakers that happened to be the largest I’d ever seen.
As we started talking, ideas about technology, AI, product design, and business history seemed to just stream out of this guy. I realized his LinkedIn header might not be an overstatement. There was a good chance I was talking to “The Best Seven Foot Engineer in the World.”
After becoming the Best Seven Foot World of Warcraft Player in the World (he and his team were also ranked #1 in North America, irrespective of height) in his late teens, Brandon’s obsession shifted from video games to machine learning, which led to a job as a ML engineer at Uber in 2014.
But ultimately, he had a deeper obsession: biology. Dealing with the challenges of moving through the world with a stutter, Brandon has an acute awareness for the pain of pathology and the frustration that comes from our inability to restore physiology.
So he jumped from tech to biotech, joining a cancer detection startup called Freenome as one of the first employees. As the company scaled rapidly, Brandon moved to Spring to help scale their platform and refine their product strategy.
Spring presented an interesting set of challenges. The business had built an exciting AI-powered platform for analyzing high-throughput images that were captured at scale in their lab. While they originally started with a thesis to develop longevity drugs, it became increasingly clear their strengths were in platform and technology development.
So Spring decided to pivot “from running its own discovery programs to collaborating with the larger scientific community through partnerships and software.” Brandon was tasked with helping to productize the platform. But in the Fall of 2023, he decided to leave and rethink what selling AI to biopharma might look like starting from a blank slate.11
That Fall, Brandon wrote an epic blog post on this topic. It was part reflection on past experience, part catharsis from his struggles, and part manifesto for how things could go differently in the future.
He made the following observations:
There are three fundamental truths you need to understand if you want to use AI to create huge value in drug discovery:
The further you are from the drug program decisions, the less value you create
The further the decisions you influence are from the commercial + clinical stages of drug discovery, the less value you create
The decisions that create the most value are choosing the right target/phenotype, reducing toxicity, and predicting drug response + choosing the right target population
Brandon derived these tenets from firsthand experience. Drug programs at the very start of their journey are worth astonishingly little. In fact, for companies with late-stage assets, public investors can assign negative enterprise value to early programs because of the risk and capital requirements.
But as risk is retired through clinical development, value increases dramatically. In a toy example, Richard Murphey from Bay Bridge Bio showed how a program worth $3M at the outset can grow to over $1B after a successful Phase 2 study demonstrating efficacy.

Selling tools and tech for the long tail on the left is hard. In theory, selling tools and tech that help guide decisions later in development would be much better. Based on this logic, Brandon developed a thesis for a new business.
Out of the high-value problems he outlined, reducing toxicity risk felt like the best opportunity. Convincing people to take on novel target risk is hard. And predicting drug efficacy is even harder—it’s the Holy Grail of drug discovery! But it felt like there would be strong pull for a product that flagged toxicity risks in molecules people were already developing.
This vision became Axiom. Roughly half of the drugs tested in clinical trials fail due to toxicity. Axiom wants to change that.
Amplify, the VC firm I ultimately joined, led Axiom’s first financing. And I wrote an angel check into the round out of my own personal savings. It felt like the right choice to bet on The Best Seven Foot Engineer in the world. Toxicity didn’t stand a chance.
Axiom’s strategy is unique. Brandon co-founded Axiom with Alex Beatson, a talented computer scientist with experience leading ML teams at platform biotech companies. A lot of what they do rhymes with how people have built platform companies in the past.
They generate massive amounts of proprietary data. So far, over 100,000 molecules have been screened in primary human liver cells, which required correctly identifying and labeling nearly 400 million cells with a computer vision pipeline.12 This lab data is integrated with another data set of over 10,000 molecules annotated with toxicity outcomes from human clinical trials. Both of these data sets grow every day.
But they don’t use this data platform to make a drug pipeline or strike traditional discovery deals. They use it to ship a product. Axiom integrates their AI predictions into a beautiful, modern web application. Additionally, they offer computational and experimental services for clinical risk assessment. Multiple leading pharma companies are now using the platform to screen their drugs.
Amgen has internal models that guide their R&D decisions. Axiom is building a suite of models to guide clinical decisions. Already, Axiom’s models outperform many of the current experimental toxicity assays used in discovery.
Here, Illumina isn’t the right analogy. Rather, this business could resemble Cadence Design Systems, which provides electronic design automation software to the semiconductor industry. Cadence’s product is so critical that they generate over $3B in annual revenue from software and IP licensing.
Imagine a future where Axiom’s AI is so good that it would be a fiduciary liability to make a decision to advance a drug program without using it. Cadence has already achieved this status in the semiconductor industry. Owning this type of platform for biopharma would be pretty valuable.
Our first story was about compute as a new reagent for biological discovery. Next, we considered the value of replacing existing experiments with computational simulation. Here, we are talking about the development of AI models that can produce information no existing experiment can rival. In other words, a net new capability.
Axiom is working hard to tackle toxicity. But the other problems Brandon outlined are still big bottlenecks. Discovering new drug targets is hard. Drugs still routinely fail in Phase 2 trials because they lack efficacy. We still struggle to identify the right patient populations for clinical trials. The list of problems like this is long.
So let’s generalize this story into another tangible prediction about how big of an opportunity this is for new startups.
Ten years from now, $X million will be spent per drug program on AI tools for making critical decisions, and Y% of that spend will be captured by new startups developing these models.
Historically, biotech has been synonymous with biopharma. The overwhelming majority of the venture dollars pointed at this market flow into businesses making new drug products. The central source of value is clinical assets.
While there have been large technology businesses like Illumina, they are somewhat anomalous. Selling software solutions into pharma is hard. And despite the growth of the contract research market, the expected returns from investing in CROs are a match for private equity, not venture. The revenue for most CROs grows linearly with headcount, not exponentially like a software or therapeutics business. (Sort of like consulting.)
Because of this, the growth of venture investment into AI biotechs selling technology rather than drugs is met with skepticism. Something about this technology platform shift has to be different for this to be a good idea. I think there is a chance this time is different.
I just told you three stories about how this could be true. I use the word story intentionally. These are narratives about how our industry could evolve, not deterministic models. Nobody knows the answer.
Frankly, we should hope that infrastructure for our industry becomes more investable. We are in continual pursuit of beautiful medicines. That is rightfully the North Star. But our relative underinvestment in shared infrastructure requires constant reinvention of the wheel, which is highly inefficient.
The resources we do share are not great. People like working with CROs about as much as they like going to the dentist. (Sorry, dentists.) We lack the market competition that leads to beautiful product experiences.
The tech industry has invested heavily in infrastructure. As a result, software developers get to use tools like Modal and Vercel, which are genuinely delightful products. I want a future where biologists have delightful tools, too.
Crucially, better infrastructure could expand our ambitions for biotech. Right now, R&D is so expensive and slow that it’s hard to actually generate returns without focusing on high-value drugs. We are still in the Tesla Roadster era.
But with better shared tools, we can move faster towards a future of sustainable abundance where our world runs on biology.
Thanks for reading this essay on AI infrastructure for biology.
If you don’t want to miss upcoming essays, you should consider subscribing for free to have them delivered to your inbox:
Until next time! 🧬
I plan to write more about this soon. I think AI will have a larger impact on the economics of discovery than initially meets the eye.
I’ve seen numbers from $7B to $15B with most centering on $10B, so I’m using ~$10B and not assuming false precision.
Here I’m using the growth rate that Roche projected during their 2025 Diagnostics Day.
The remaining 16% was research services.
At its peak, Illumina had a ~$75B market cap. The subsequent decline in value is a very, very long story.
Another beautiful example is this paper from 2021 using AI models to understand properties of viral evolution and escape.
Another interesting rabbit hole in studying the AI stack is the growth of “neoclouds,” which SemiAnalysis has rigorously analyzed.
Thanks in part to technologies like 10X Genomics that we discussed earlier.
This evaluation framework seems to have gone slightly off the rails. Challenge participants have learned that applying somewhat arbitrary data generations can propel them to the top of the leaderboard. Figuring out the right benchmarks for these models is a nontrivial problem.
There are ways to estimate this that give bigger and smaller numbers, so I’ll just stick with Regev’s estimate as a rough order of magnitude.
Ultimately, pivoting the Spring platform to this model did prove to be too difficult. Spring wound down their efforts before ultimately finding a home at Genentech.
They started with liver cells because one of the major categories of drug toxicity is drug-induced liver injury, because of how small molecules are metabolized.
As an investor in Illumina and a few other small biotech companies, and as a non-biologist, I welcome this very interesting article. It explains a lot to me and I keep fingers crossed that I will recieve at last some return on my investment….. thanks and keep going!
Really nice essay! Thank you for sending it out!
I'm thinking about Brandon White's three truths. Does #3 not contradict #1 and #2? Recapping:
1. The further you are from the drug program decisions, the less value you create
2. The further you are from the commercial + clinical stages of drug discovery, the less value you create
3. The decisions that create the most value are choosing the right target/phenotype, reducing toxicity, and predicting drug response + choosing the right target population.
Isn't choosing a target, or a phenotype, or a population of likely responders, very far from the commercial and clinical stages? Those sound like academic research questions to me. I've never worked in drug development so I'm curious to hear your take.