
Manifold Bio: Barcoded Biologics
Designing medicines that go where we want them to

Welcome to The Century of Biology! This newsletter explores data, companies, and ideas from the frontier of biology. You can subscribe for free to have the next post delivered to your inbox:
Today’s essay is about Manifold Bio, a promising Boston-based startup that spun out of the Church Lab at Harvard. In many ways, their story is a continuation of the key themes of this newsletter. Alongside Dyno Therapeutics, a company I’ve previously written about, the founders of Manifold are some of the world experts in combining cutting-edge DNA technologies with machine learning. They’ve also thought deeply about the best platform strategy to realize the full potential of their inventions.
We’re going to dive deep into the history of large-scale DNA libraries, the potential of multiplexed protein measurement in living organisms, and the business decisions Manifold has made in pursuit of breakthrough medicines.
Enjoy! 🧬

In biology, great technologists have a way of measuring the unmeasurable. And Manifold had done just that.
They had fifty antibody medicines, each carefully designed to traffic across the blood-brain barrier and dissolve the plaques thought to drive the progression of Alzheimer’s disease.
But testing each antibody would require over five hundred monkeys. Even if they could procure this many animals, the cost—both financially and ethically—would be enormous.
Instead, Manifold ran the study with a molecular sleight of hand. Using their protein barcoding system, they resolved the distribution of each drug in the body in parallel, requiring an order of magnitude less animals. And what they saw was incredible.
But in order to explain how they got here, I’d like to tell you a story.
Innovation rarely follows a linear trajectory. When one bottleneck is addressed, it often reveals another one not too far behind it. For this reason, progress is shaped more like a staircase, with discontinuous steps upwards that compound over time.
Over the last fifty years since the biotech industry started, many of our foundational capabilities have compounded like this.
The first “killer app” for Genentech was simple in hindsight: producing an existing protein in microbes instead of animals using recombinant DNA technology. Gradually, dozens of advances stacked on top of each other and expanded the scope of what we could build with DNA. Monoclonal antibodies emerged as a full-fledged app store, with over one hundred drug approvals solidifying biologics as a new cornerstone of medicine.
Along with the app store came an entire suite of tools for app developers. Multiple generations of antibody discovery technologies were invented, each building on previous efforts. Now antibody developers have a smorgasbord of approaches to choose from to tackle their specific problem.
Like any other technology, these techniques are quickly maturing and becoming commoditized. Biotech companies can choose from a large number of different vendors that offer antibody discovery services. We are getting really good at identifying proteins that bind to other proteins—binders.
At this point, an antibody discovery campaign rarely fails at the stage of finding binders. If that weren’t enough, new AI technologies are making it possible to computationally design protein binders in a matter of minutes. Imagine a future where every scientist with a laptop has this capability.
But a binder is not a drug.
This simple fact helps to explain one of the most surprising disconnects in our industry.
As Jack Scannell observed in 2012, despite all of these extraordinary developer tools, “the number of new drugs approved per billion US dollars spent on R&D has halved roughly every 9 years since 1950, falling around 80-fold in inflation-adjusted terms.”
In one of his “diagnoses” for this decline in efficiency, Scannell points to “The ‘basic research–brute force’ bias.” We have a tendency to over-invest in the discovery technologies that can be rapidly scaled and industrialized. But the ability to be scaled doesn’t necessarily correlate with a tool’s ability to help successfully predict a drug outcome.

So, we’ve made huge strides in finding new starting points for drug programs. But our downstream techniques for discerning their quality haven’t improved at the same rate.
We can now screen hundreds of billions of possible antibodies to find hits. Once it’s time to see how they behave in a living system, we still test them one by one in mice.
Manifold Bio has a vision to change that.
Founded in 2019 during the onset of the COVID pandemic, Manifold got started with nothing more than a small team and an idea. What if we could point our exponentially improving DNA technologies at the bottlenecks that come after we find drug starting points? What if we could test massive numbers of drug candidates in a single animal experiment?
Fast forwarding to the present moment, this is no longer just theory.
Using sophisticated molecular engineering, Manifold has built a drug discovery platform capable of screening over 100,000 antibodies in the type of in vivo experiments in organisms that would typically test one antibody. Narrower screens can resolve over 1,000 antibodies in the body at a resolution so precise it would be like detecting a single grain of sugar in over 120 Olympic-size swimming pools.
Along the way, Manifold has raised over $70M, recruited word-class drug discovery talent, and developed a pipeline of promising drug candidates that aim to precisely target one of the most challenging organs to develop biologics for: the brain.
Just like the industry’s evolution, Manifold’s story involves a number of crucial—and often serendipitous—insights and pivots stacking on top of each other to arrive at their current position.
In fact, if it weren’t for a throwaway elective at the end of Gleb Kuznetsov’s time at MIT, Manifold probably wouldn’t exist.
ML²
During his undergrad at MIT, Kuznetsov didn’t study biology. To the contrary, he actively avoided it. Biology didn’t feel like an engineering discipline. It wasn’t until the last credit of his Master’s degree in computer science that one course changed his tune.
In a class with Manolis Kellis, a Greek computational biologist who can preach about his discipline with the fervor of a church pastor, Kuznetsov saw the future of biology painted in a very different light. With rich data streaming out of modern lab instruments and DNA sequencing machines, the field started to feel like an open frontier where somebody with his computational skillset would soon become the protagonist.
Looking back on the experience years later, he said, “Taking that class was like a moment in a video game where you walk into the correct room, and the music starts getting louder, so you know you’re doing the right thing.”
After a brief stint as a software engineer at Google, the music led him to George Church.
Church is a walking embodiment of the biotech revolution that Kellis outlined. For decades, a seemingly endless stream of advances has flowed out of his research lab at Harvard.
He played a key role in inventing modern high-throughput DNA sequencing and synthesis tools, programmable gene-editing technologies, longevity therapies, “de-extinction” strategies, genetically recoded organisms, molecular data storage, AI-based drug design approaches, and many, many more projects that read like science fiction.
Dwarkesh Patel recently introduced him by saying, “it would honestly be easier to list out the major breakthroughs in biology over the last few decades that you haven’t been involved in.”
Kuznetsov pitched Church on a simple idea. He’d join the lab as a programmer and help build any software tools that were needed. In exchange, he’d get the chance to learn how to design and run experiments. Church happily agreed. “I was flattered that I could possibly lure somebody away from Google with a much lower salary,” he told me.
Ultimately, Kuznetsov went so far down the research rabbit hole that he enrolled in Harvard’s biophysics PhD program to pursue a graduate thesis with Church.
At the time, the Church Lab had an absolutely extraordinary concentration of talent. Kuznetsov overlapped with scientists like Sri Kosuri, Dan Goodman, Eric Kelsic, Surge Biswas, Marc Lajoie, Lexi Rovner, and Adam Marblestone, who have all gone on to become rising stars in science, philanthropy, and business.
What attracted many of these brilliant people—aside from the general appeal of training with a legendary researcher—was the unique environment Church cultivated. Unlike other labs where graduate students mainly focused on their own projects, collaboration and cross-pollination, especially between disciplines, was actively encouraged. And technology development wasn’t treated like a second class citizen to basic research.
Tinkering with the latest technologies and exploring their boundaries was considered to be a normal activity, not an unwelcome distraction.
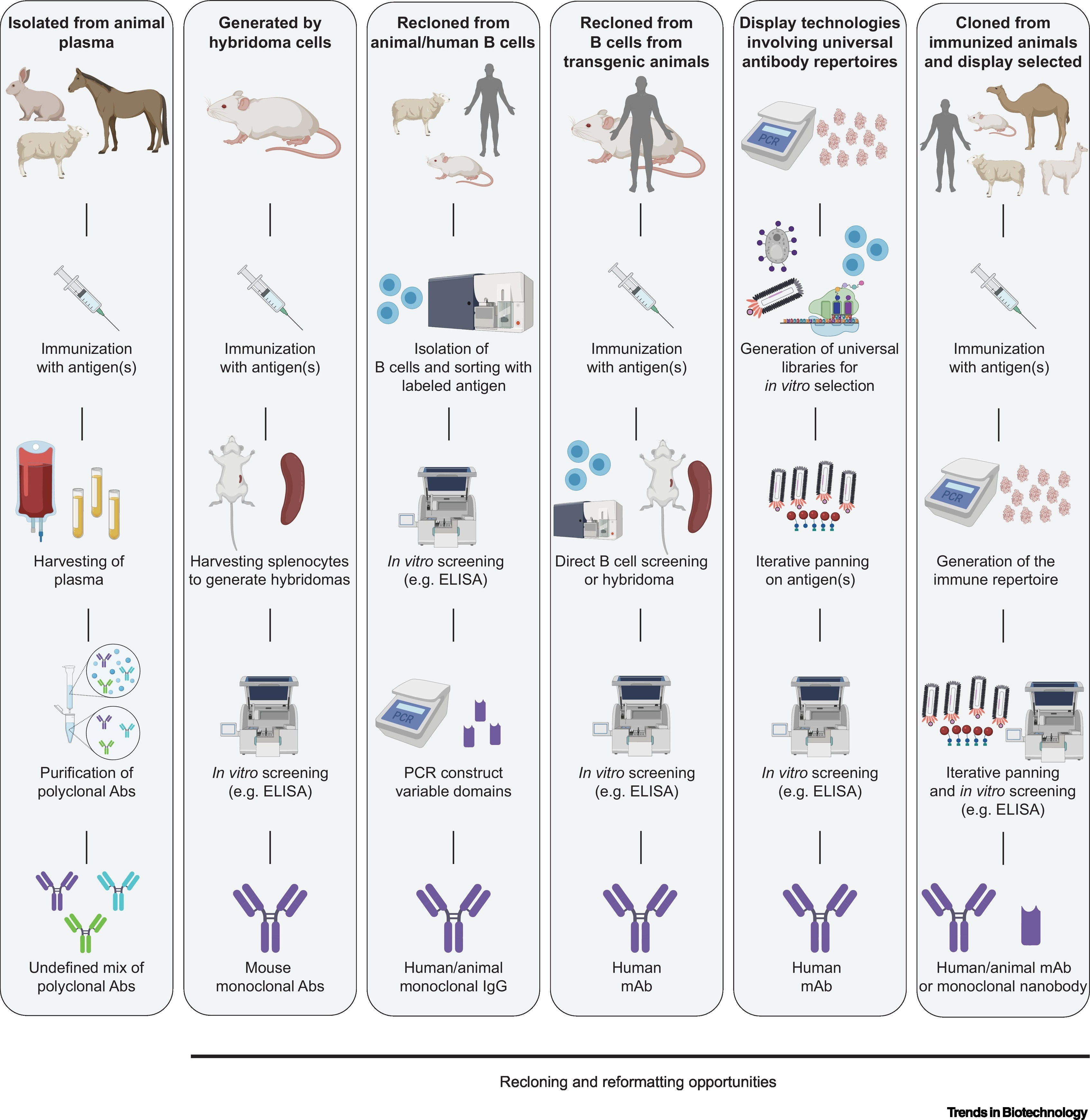
One of the most exciting technological frontiers in this era was DNA synthesis. After the Human Genome Project had completed in 2003, it was clear that “DNA reading” (sequencing) approaches vastly exceeded our “DNA writing” (synthesis) capabilities.
But since the 1990s, companies like Affymetrix had been developing systems called DNA microchips. Using techniques from the semiconductor industry, they invented approaches for synthesizing billions of short DNA polymers called oligos (short for oligonucleotides) on miniature glass wafers.
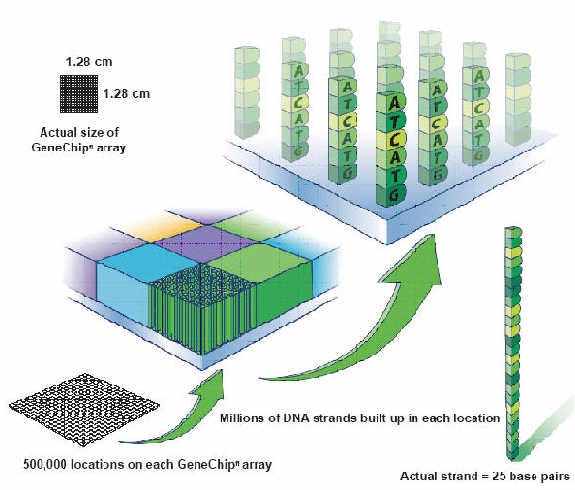
Initially, these chips were used as an analysis tool. Distinct nucleic acid sequences in a sample could be detected when they bound to the oligos on the chip.
Beyond detecting other DNA molecules, the amount of DNA on the surface of these chips was so minuscule that it was unclear it would be useful for anything else. But the Church Lab started tinkering.
In 2004, just one year after the Human Genome Project, they found an extremely clever use case.
They came up with a way to cleave the DNA off of the chip, effectively harvesting a “pool” of these tiny oligo sequences. To get around the small volume of DNA, they would flank the sequences they wanted larger quantities of with PCR primers that they called “adaptors.”
By including these sequences, they could initiate a molecular chain reaction that would create billions of DNA copies.
Finally, they would cut off the adaptors using restriction enzymes—the same type of enzyme used to produce recombinant DNA that kicked off the biotech revolution in the first place.

It was nanotechnology in action. By “programming” the microchip with stepwise reactions, they could produce large quantities of short chunks of DNA that could be used for a wide variety of applications. One obvious use case was to stitch them together into complete gene sequences.
They published a demonstration of this in Nature, synthesizing 21 distinct genes for one experiment. It was an extraordinary feat at the time.
The genius was in the skillful synthesis of three powerful DNA technologies.
DNA microchips + PCR + restriction enzymes = magic.
Once the paper was out in such a widely read journal, Church told me he thought gaining large-scale adoption was “going to be a piece of cake.” It felt like an obviously important technology for large-scale testing of all the hypotheses being developed by the new field of genomics.
To his surprise, few people knew what to make of it. For over a decade, his lab had “this entire incredible field to ourselves,” he said. And so they kept tinkering away, exploring application after application with little competition.
In 2009, they published a landmark paper describing the use of complex pools of synthetic DNA for genome engineering. The technology, called Multiplex Automated Genome Engineering (MAGE), made it possible to introduce billions of genetic variants per day to rapidly evolve organisms toward desired traits—such as optimizing the rate of production of a desired molecule.
At a high level, Church refers to this as Super Evolution. “In principle, evolution might incorporate a few base pair changes in a million years. Now we can make billions of changes in an afternoon,” he said recently.
This was the massive playground that Kuznetsov and his brilliant lab mates freely explored.
In his first few years in the lab, Kuznetsov worked with a small team to publish a string of papers using these tools to genetically recode microbes—creating or deleting entire codons—and optimize their genomes. They wrote, “by recoding bacterial genomes, it is possible to create organisms that can potentially synthesize products not commonly found in nature.”
These were ambitious, pie-in-the-sky research projects to make synthetic organisms.
Over time, though, his interests evolved. Two of his neighbors at the bench, Eric Kelsic and Pierce Ogden, had more translationally relevant ideas in mind. They wanted to use these DNA technologies to engineer therapeutically relevant molecules.
Kelsic had originally studied physics but was drawn to the potential of engineering biology. By the time he arrived at the Church Lab, he was interested in pursuing a project with near-term commercial relevance.
Ogden, who grew up in the Bay Area, originally studied at the University of San Francisco, a small Jesuit college tucked next to Golden Gate Park. After peppering the TA of a graduate-level bioinformatics course with questions, she told him to seek out research opportunities in U.C. San Francisco’s world-class labs on the other side of the city.
There, Ogden became deeply obsessed with technology development. He interned in a number of labs before becoming a technician in the Small Molecule Discovery Center run by Jim Wells. For two and a half years, Ogden spent his time programming, building databases, learning the ins and outs of lab robots, and optimizing drug discovery assays.
And then one book changed his trajectory.
Regenesis: How Synthetic Biology Will Reinvent Nature and Ourselves, is Church’s manifesto on the future of bioengineering. Narrating the advances in DNA sequencing and synthesis, he paints a picture where writing “genetic software” is the most important technology of the future.
After reading the book, Ogden had a simple conclusion: he needed to go work with this guy.
So, he moved across the country to start graduate school and join the lab.1
Together, Kelsic and Ogden decided to work on engineering better viral vectors for gene therapy. Using the programmable DNA synthesis techniques, they could create “multiplexed libraries” of the vectors, meaning that a large number of genetic designs (library) were created and tested in parallel (multiplexed).
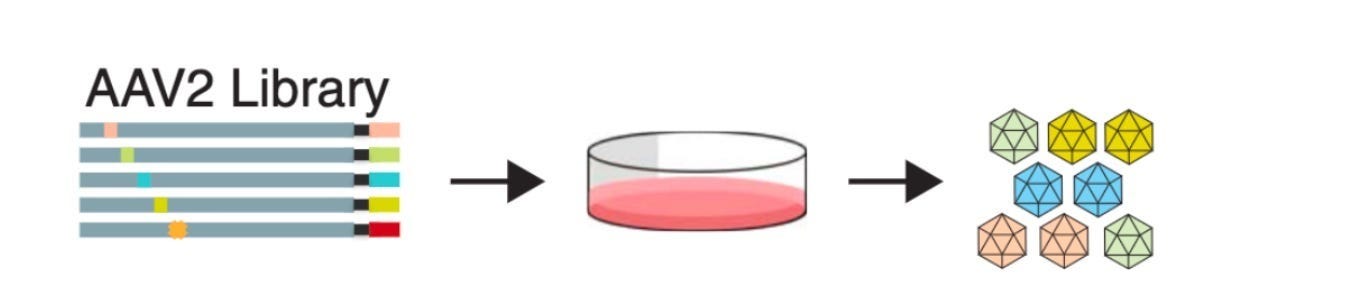
In 2019, they published impressive results from this approach applied to the adeno-associated virus (AAV) genome. This line of research ultimately became the basis of a company called Dyno Therapeutics, which Kelsic still runs.
Rather than joining Dyno, Ogden pursued a different technology direction: protein engineering.
Compared to proteins, gene therapies have a major engineering advantage: their payloads consist of DNA. This meant that it was possible to naturally apply all of the DNA technology tricks the Church Lab had refined over the years.
Proteins, which are chains of amino acids, lack this immediate advantage. But given their centrality in biology—as well as their enormous market share in both the research tools and therapeutics markets—Ogden thought it was worth figuring out a way to use multiplex libraries to engineer them.
In parallel to the AAV project, Ogden, Kuznetsov, and Surge Biswas formed a small team to explore this direction. To start, they worked on engineering green fluorescent protein (GFP), an important research tool that, well, glows green! Many efforts had been made to make it glow even brighter, but GFP has a complex structure that made progress difficult. They wanted to see if they could do any better.
So they took a Super Evolution approach.
Combining gene synthesis technology and error-prone PCR, which introduces a wide range of “mutations” while it makes copies of the DNA, they produced roughly 300,000 variants of GFP. Using yet another technology invented in the Church Lab called FlowSeq, they sorted the variants by their brightness and sequenced the DNA that produced them.
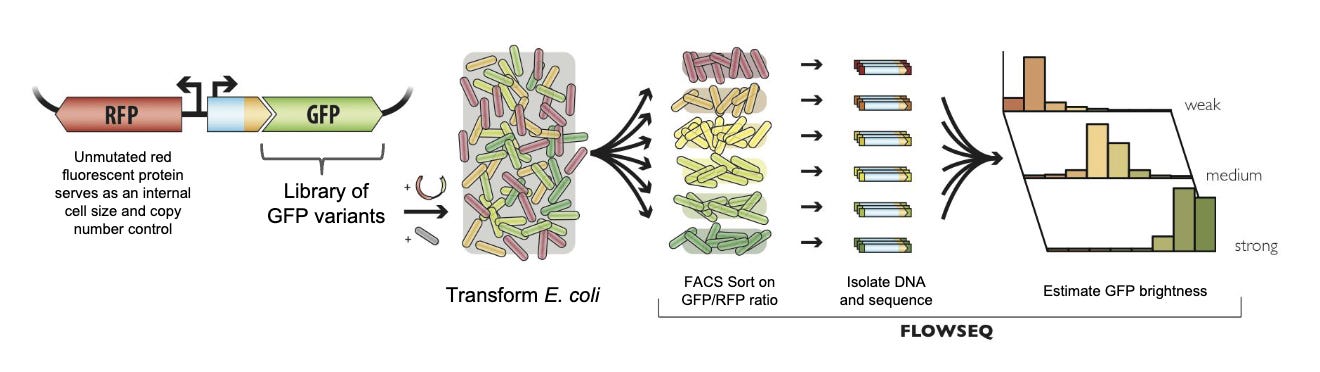
This created a data set of genetic variants matched with protein brightness.
Next came the question: what was the best way to analyze this data set and predict new designs?
It was a large data set…
With lots of paired samples of inputs and outputs…
Which made it a perfect fit for machine learning!
This was not by accident. Over the years, a number of Church Lab members had become ML early adopters. It was another technology to explore—and to mix and match with other tools.
Sam Sinai and Eric Kelsic had prototyped early generative models for biological sequences, and a major theme of both the AAV and protein engineering projects was to use ML for “machine-guided design.”
What does this mean?
Consider how Evolution works. An organism has a genome that encodes a set of traits. These traits impact fitness, which is the likelihood of reproduction. At any given time, it’s highly unlikely that an organism has the genome with the greatest possible fitness. Over time, random mutations provide the substrate for Evolution to effectively sample from the underlying landscape of possible genome sequences adjacent to an organism’s current genome.
This fitness landscape is often visualized as a three-dimensional space with peaks and valleys. Evolution is gradually selecting the sequences at higher and higher points of fitness.

For genome or protein engineering, we get to pick what sequence we are optimizing and what fitness is. For example, optimizing the GFP gene sequence to encode a brighter protein.
Technologies like directed evolution already harness this type of approach to engineering.
But the major conceptual advance for machine-guided design is that we can use machine learning models to predict the fitness impact of mutations. By doing that, the models need to learn an approximation of the underlying fitness landscape of that sequence.2
Having access to this approximation makes it possible to sample much farther out from the original starting point of the sequence.
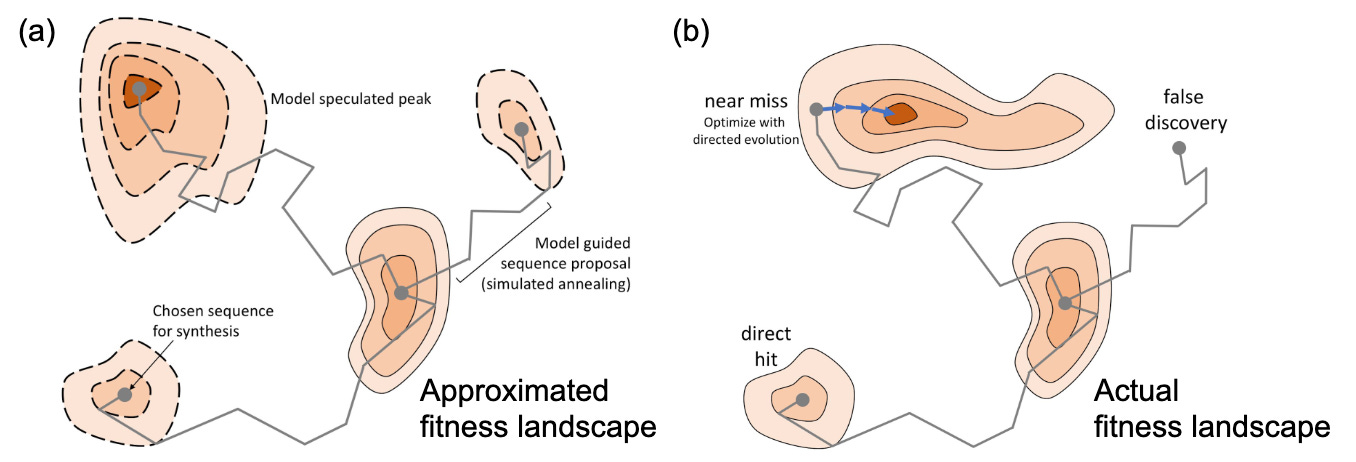
It’s a technology to learn the rules of Evolution—and how to steer it!
Or, ML² (multiplex libraries x machine learning), as Church calls it.
These incredibly powerful technologies proved to be quite complementary.
Using this approach, they identified advantageous combinations of mutations far outside the “local neighborhoods” of possible sequences that other technologies sampled. They could produce much brighter GFP—steering the Evolution of a complex and important protein.
With these results in hand, they proceeded to completely bury the lede.
In June of 2018, they published a short, highly technical, ten page preprint on bioRxiv entitled Toward machine-guided design of proteins. Nobody ever bothered to shepherd the study all the way through the peer-review process into a prestigious journal. Years later, another group’s ML-guided evolution of brighter GFP was published in Science.
But the publication strategy was an afterthought. They had already convinced themselves that ML² for protein engineering had huge potential. Unlike other academics, they were beginning to ask themselves if this could form the basis of a company, not a CNS paper.
mCodes
With over 400 publications that have been collectively cited over 200,000 times, it’s safe to say that George Church has had a prolific scientific career. His involvement in the biotech industry is equally extreme. Church maintains a spreadsheet of his commercial involvements over the years. It now has well over 700 rows.
He loves seeing technologies translated out of the lab and into the world. So when his trainees started pursuing entrepreneurship rather than academic careers, it didn’t bother him in the slightest.
One of the early successes was AbVitro, an oncology startup co-founded in 2012 by Francois Vigneault, a French-Canadian postdoc in his lab. After only three and a half years, the company was snapped up by Juno Therapeutics for $125M, delivering a 40x return on investment in a short time period.3
Soon after AbVitro was started, Luhan Yang raised $38M to found eGenesis, a company with a sci-fi vision to genetically engineer pig organs for human transplantation.4
These early spin-outs led by trainees quickly created an “infectious entrepreneurial culture,” according to Church. More and more lab members started to successfully raise money to commercialize their research.
As Kelsic and several others left to start companies, Kuznetsov, Ogden, and Biswas wondered: “why not us?” They felt that they had great technology and could figure out what it took to successfully pitch their idea and build a business around it.
Kuznetsov started to make moves to figure the latter part out. While they kept working on the protein engineering project, he defended his PhD thesis and transitioned into a role on the Advanced Technology Team at the Wyss Institute. It was part technology development, part entrepreneurial information gathering. Between coding and pipetting, Kuznetsov talked to as many industry experts and potential customers as he could.
Early on, the commercial ideas were broad and unspecific. At one point, Kuznetsov, Ogden, and Biswas pitched a VC on a vision to build a protein engineering company that could help make “proteins for therapeutics, genome editing, materials, and reagents.” Name a major protein market, they would solve it.
After an unsuccessful pitch, the team realized they needed to refine their focus. Biswas decided to double down on machine learning methods development with another group of researchers in the Church Lab.5
Kuznetsov and Ogden realized they needed to decide on one market to clarify their pitch. One of the central ideas was that they could use ML² to “learn the binder code” that dictated how antibodies recognized their protein targets.
A conversation with Dane Wittrup, a co-founder of Adimab (one of the most successful antibody design businesses), gave them another wakeup call. He poured some cold water on their binder design ideas, pointing out how competitive this market had become with a litany of different screening technologies.6
While it might be tough to break through the noise with a new screening system for finding binders, he pointed out the greenfield space for technologies that helped people advance their antibodies through the rest of pre-clinical development.
In particular, in vivo experiments, which test drug candidates in animals, had remained basically unchanged since the start of the biotech revolution. More conversations helped to strengthen their conviction that solving this problem would deliver real value.
A new idea clicked into place for Ogden.
His earlier project with Kelsic had done exactly that—but for AAVs, not antibodies. They were able to screen massive libraries of possible AAV designs in a single animal experiment.
What if they could achieve the same result for antibodies?
Doing this would require solving a crucial problem: figuring out how to actually keep track of where the different antibodies were going and what they were doing.
Unlike antibodies, AAV naturally shuttles DNA into the nucleus of cells. In order to easily keep track of different designs, they introduced DNA barcodes—short stretches of nucleotides that could be quickly discriminated by DNA sequencing—into the genetic payloads of the viruses.
These synthetic DNA signatures let them quantify which AAV mutations were driving more efficient production or delivery of therapeutic payloads.
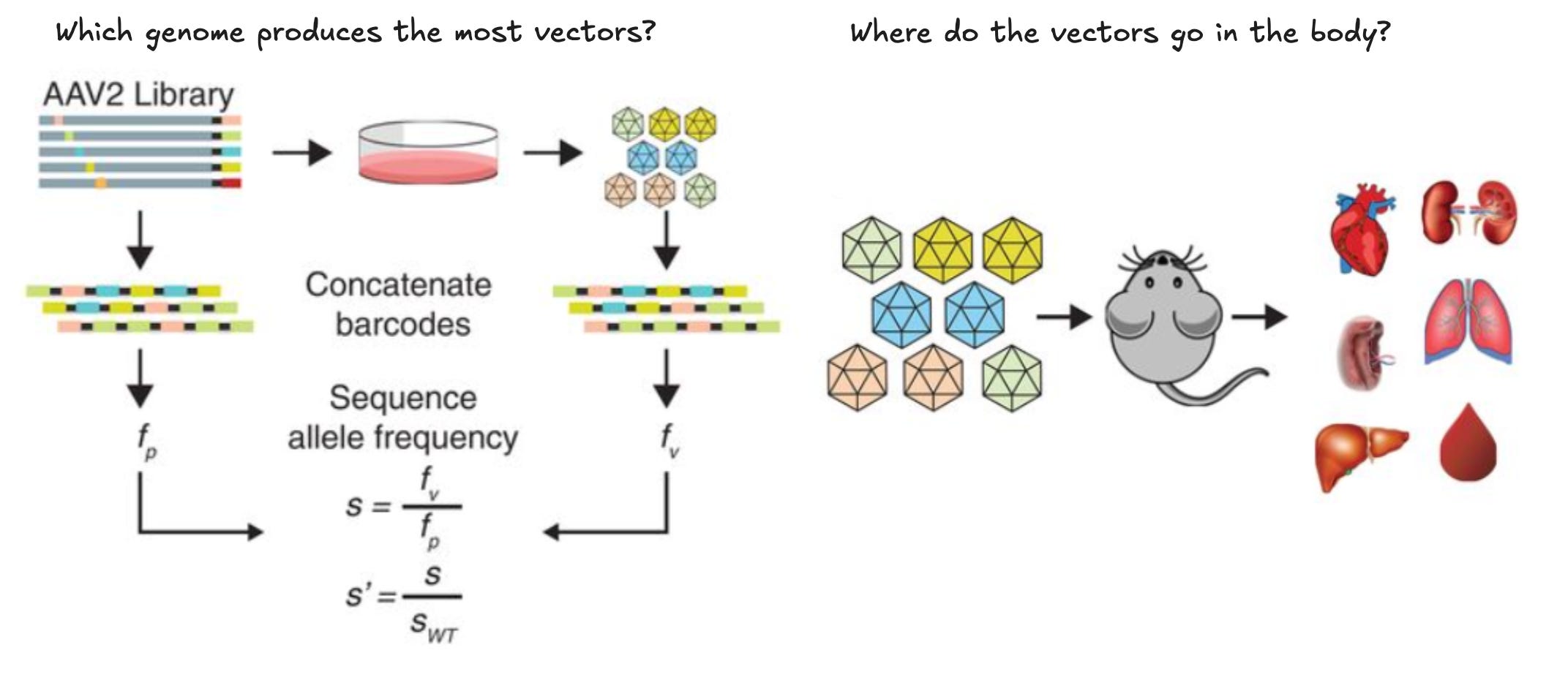
Unfortunately, stitching DNA barcodes onto antibodies was a non-starter. The reaction for joining antibodies with unique DNA sequences is much less scalable. And even if they could do it, adding such a large and negatively charged molecule would confound their measurements.

They devised a plan to skirt around this issue.
Using ML², they’d screen a massive number of antibodies against a massive number of antigens in a giant all-by-all experiment. By screening every antibody against every antigen, they could find antibody-antigen pairs that were highly specific to each other.
It would be like building a big set of lock-and-key pairs.
Now, what if they could discretely put the key (antigen) on an antibody they wanted to track?
And what if they attached DNA to the lock (antibody) that would bind it?
This would convert antibody measurement into a DNA barcode detection problem just like for AAV.
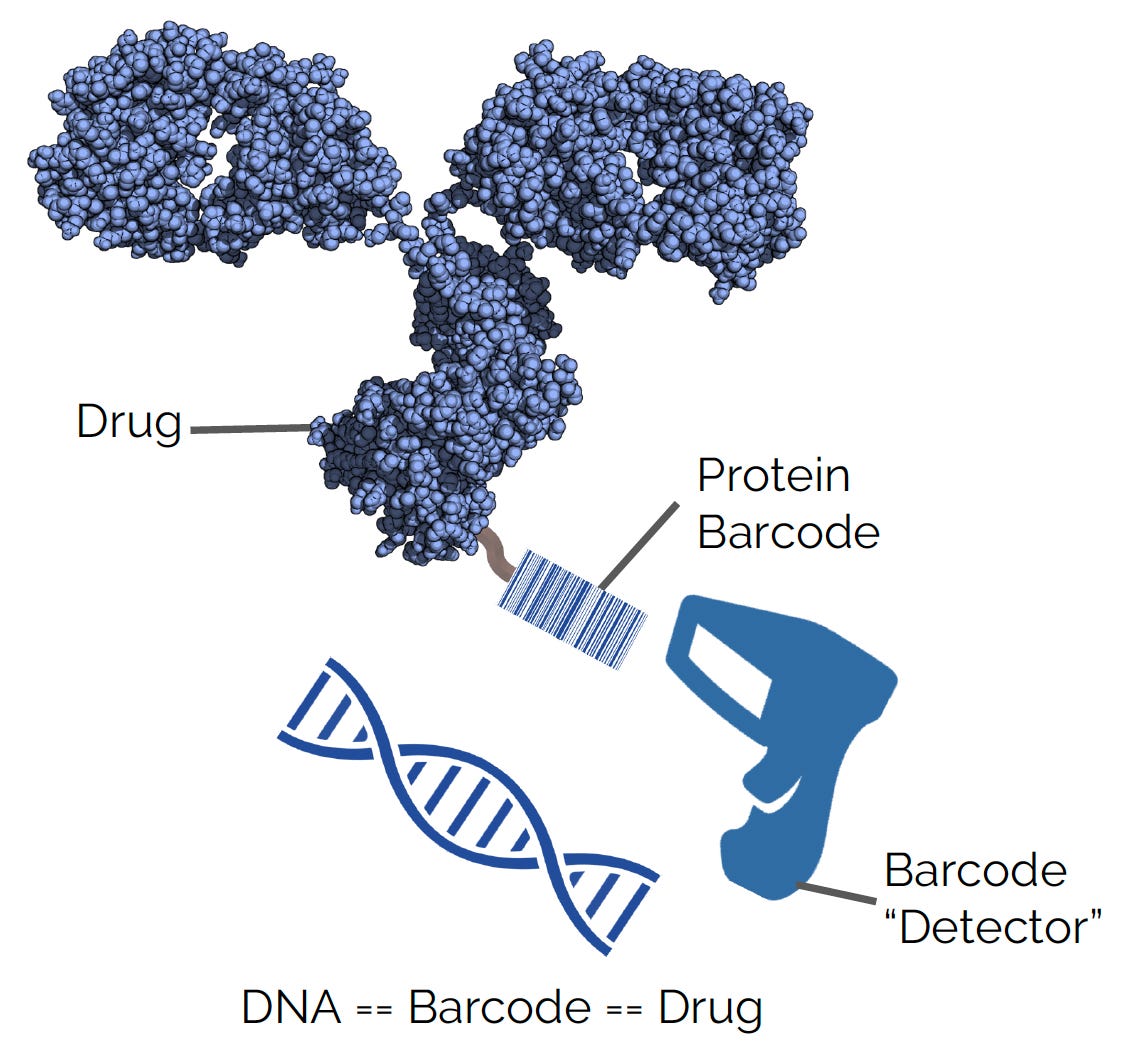
Simply put, they aimed to “turn counting proteins into DNA sequencing.”7
If they could develop these protein barcodes—which they called mCodes—they could track proteins much more easily. In theory, they could multiplex in vivo experiments, testing hundreds, or even thousands, of drug designs every animal experiment instead of just one.
While compelling, all of these ideas were just that—ideas.
To change that, they incorporated a business named Manifold Bio in March of 2019, alluding to the enormous mathematical space of possible protein sequences they navigated with ML². And in January of 2020, they started their first dedicated fundraising process.
It turned out that something else was getting started right around the same time: the COVID pandemic. As they pushed to get their new business off the ground, the entire world—including the entire global economy—ground to a halt around them. Many investors kept their hands in their pockets and waited for things to stabilize.
A few months in, Seth Bannon at Fifty Years wrote the first ~$1M check that would help catalyze the rest of the round. After dozens of Zoom diligence calls, Jory Bell at Playground Global stepped up to lead a Seed round totaling $5.4M.
Around the time the Seed round was coming together, they were joined by another co-conspirator: Shane Lofgren. After connecting at a friend’s party in Boston, it became clear that Kuznetsov, Ogden, and Lofgren shared a certain “crazy idea energy.” He also was highly motivated to have the autonomy to refine these ideas and put them into practice.
Lofgren brought a distinct set of experiences and skills to the trio. After working as a scientist at Stanford for several years, he transitioned into a role in the university’s technology transfer office. There, he pored over thousands of patents, helped research commercial opportunities, refine pitches, and broker connections to his growing VC network. When the opportunity came along, he rolled up his sleeves and worked with Atlas Venture to incubate and co-found a venture creation effort in oncology.
Lofgren met Kuznetsov and Ogden while he was building this company. At the time, he had his own set of ideas for new ventures to pursue next. But he saw two things. The science underlying Manifold seemed incredibly powerful. And the commercial ideas were incredibly raw.
Over a quickly ballooning email thread, Lofgren poked a litany of holes in Kuznetsov’s early commercial strategy. In over 2,000 words, Lofgren argued that their proposed drug programs and partnering plans were unfocused and underutilized the true advantages of the platform.
Unperturbed, Kuznetsov responded with an email to the effect of: “Well, what do you think we should focus on?” Another 2,000 words quickly landed in his inbox detailing a more focused and differentiated business strategy. Kuznetsov got excited.
Realizing that Lofgren provided a valuable commercial conduit to his and Ogden’s platform vision, he recruited him to join Manifold as a co-founder and help refine and run their business development. Lofgren quickly accepted the offer. He loved the science. And he was ready for a role with greater agency and ownership.
With a company, early team, and Seed funding in place, Manifold was ready to turn their vision for mCodes and in vivo multiplexing for biologics into reality.
Platform Evolution
For the rest of their first year in operation, the Manifold team laid the foundation for their platform. They needed to hire great scientists, build custom libraries, assays, and sequencing protocols. All of this took time. Progress was far from immediate.
But in the following year, it became clear that their mCode strategy had legs. Quarter after quarter, the number of mCodes in their toolbox kept growing. By the end of 2021, they had over 150 mCodes, effectively increasing the number of antibody designs they could track in vivo by two orders of magnitude relative to the rest of the industry.
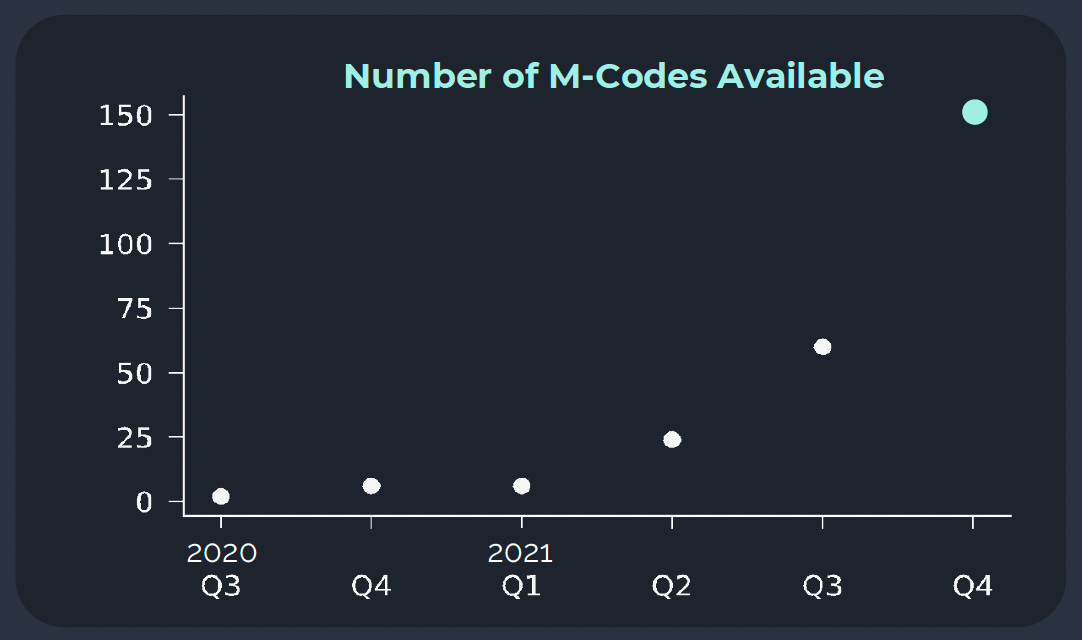
In parallel to their engineering efforts, they pursued two commercial directions. The most central objective was to use their platform to produce highly differentiated internal drug programs. Additionally, they would engage with Big Pharma companies to license and access their mCode technology.
The team thought long and hard about platform-product fit: what type of drug discovery problem would be most uniquely advantaged by the technology they had developed? T-cell engagers (TCEs) seemed like an ideal product to focus on.
TCEs are a fascinating type of biological drug.
One of the biggest breakthroughs in oncology in recent history has been the advent of immunotherapy. In particular, cell-based therapies, such as CAR-T therapy, have delivered curative results for blood cancers. These medicines work by engineering a patient’s own T-cells with a synthetic receptor to target and kill cancer cells.
While the clinical results have been extraordinary, the immense time and cost associated with personalized cell engineering have limited widespread adoption of CAR-T therapy.
TCEs aim to drive the same cell-based mechanism with the dosing simplicity of a traditional antibody. One part of the antibody binds to molecules on the surface of a T-cell. Another part binds to a tumor-associated antigen (TAAs) on the surface of a cancer cell. It’s like a sort of cellular adaptor that brings immune cells and cancer cells into physical proximity, triggering an immune response.

One of the major challenges for developing the next generation of TCEs is figuring out what TAA—or combination of TAAs—will enable precise targeting to a tumor. If the TAA is unspecific, meaning it is also on healthy cells, it can cause serious immune toxicity.
It felt like a perfect problem for Manifold’s platform to solve. No other screening approach could rapidly test hundreds of possible designs to figure out the best possible tumor-specific targeting inside of an organism. So the Manifold team started to design new TCE formats and test them at scale in vivo.
By 2022, everything was tracking positively to move forward and raise a Series A. The goal was to raise enough money to keep scaling the platform and nominate their first clinical development candidates (DCs).
But things got complicated. Just like their Seed round at the start of COVID, they found themselves in one of the most difficult fundraising markets in recent history.
Right after their Seed, the biotech market had gone on a historic bull run driven by the enormous demand for vaccines and diagnostics, coupled with incredibly low interest rates to stimulate the economy. In February of 2021, the XBI, a widely tracked barometer of biotech stock performance, hit an all-time high of $174.
Towards the end of 2021 and start of 2022, cracks started to show. Public investors started to rotate out of “pandemic trades” and assess biotech companies with far greater scrutiny. Once the Fed started to increase rates in March of 2022, the bottom fell out. The public biotech market effectively collapsed. By June of 2022, the XBI had lost two thirds of its value.
Despite the bleak macro environment, Manifold managed to push forward and close an oversubscribed $40M Series A led by Jeff Huber at Triatomic Capital that same month. To use Kuznetsov’s video game analogy, Manifold had been able to close two fundraising rounds while playing on hard mode.
With enough capital to weather the upcoming biotech winter, Manifold kept cranking on their platform and drug programs. While things were headed in the right direction, they continued to reevaluate and tighten their strategy.
As Lofgren advanced the company’s BD and partnering discussions, they started to realize a concerning pattern. At the outset, their plan was to land small pilot projects with pharma offering access to their mCode screening technology. Over time, the idea was that these pilots could serve as a toehold for landing larger discovery collaborations.
After a few attempts, problems with this plan started to become more apparent. Timelines for negotiation were long and contracts were small. Even worse, it proved to be challenging for pharma partners to adopt their tools in a piecemeal fashion.
Sure, they could provide mCodes. But what good would that do without an approach to systematically design and synthesize a complex library of antibodies to measure in the first place?
In addition to their set of mCodes, Manifold had built an in-house suite of AI tools and custom-designed antibody discovery assays specifically for this purpose. Each piece of the stack was designed to be perfectly compatible with their in vivo multiplexing technology.
Leveraging his lab robotics chops, Ogden had helped design and build an automated rig that could execute large chunks of these complex experimental workflows with the push of a button.

The mCodes were one piece of a suite of vertically integrated technologies that embodied a distinct drug discovery philosophy. At Manifold, new campaigns start with in vivo experiments that inform iterative cycles of design and testing.
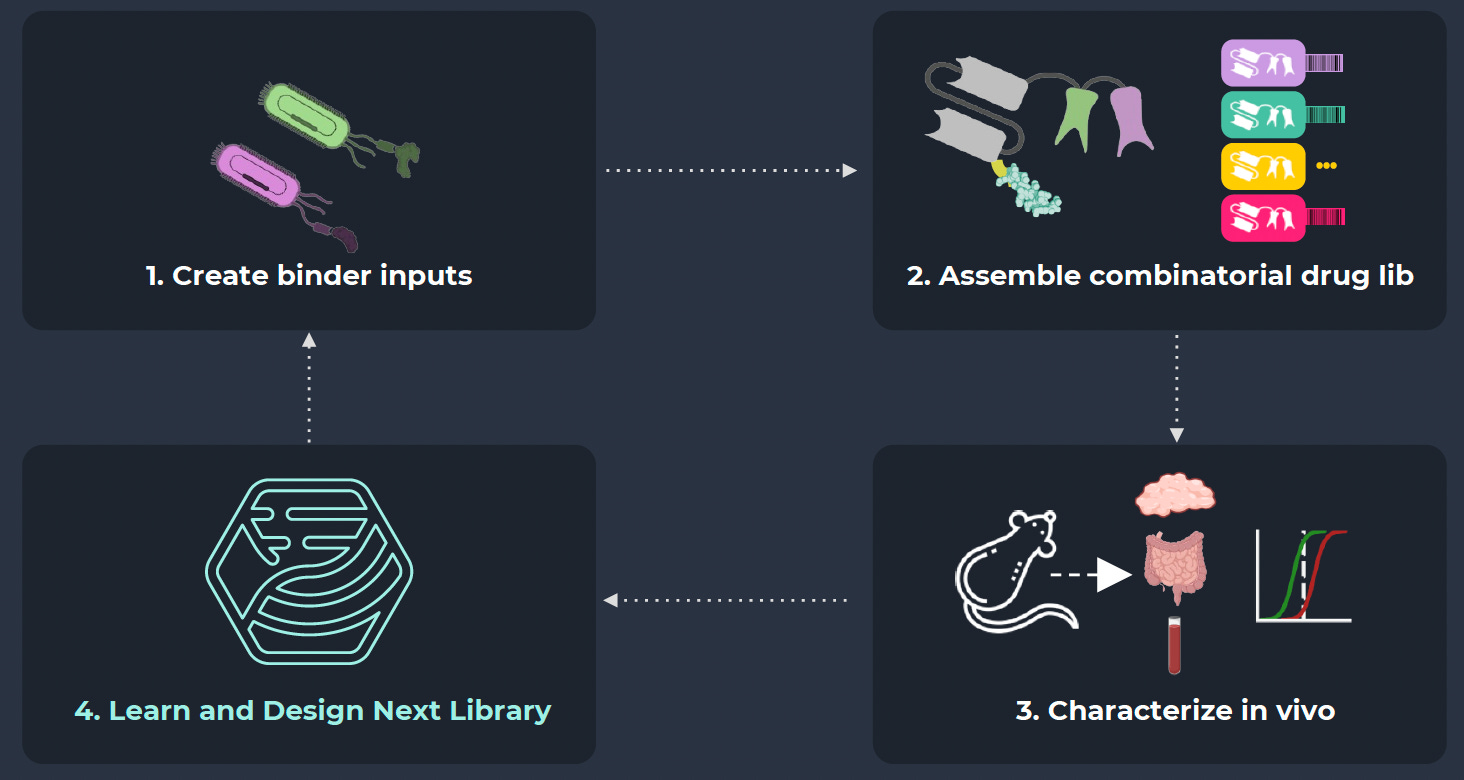
Pharma partners wouldn’t get the full benefit of the platform with in vivo multiplexing alone. Manifold realized they would need to deprioritize services contracts and prove to partners that they could be trusted as full-fledged discovery partners as soon as possible.
Ideally, Manifold would work with a potential pharma partner to scope out a drug program they could help deliver with their platform. From there, they could negotiate a collaboration agreement to deliver results in the form of new IP for chemical matter—rather than technology or services that would just be a means to an end.8
To help structure and land these larger deals, Manifold made a crucial addition to their team, recruiting the one and only Steve Holtzman to join as their Executive Chairman. Over decades on both the sell-side and buy-side of countless biotech BD deals, Holtzman had developed a coherent theory of platform value creation.
In order to drive larger partnerships over the line, Manifold knew they would need to keep advancing their internal programs to prove what their platform was capable of.
Once they had IP of their own, everything would get easier. As Steve Holtzman told me, for biotech platforms, “We don’t sell labor. We sell rights to certain applications of our intellectual property.”
Throughout 2022 and the first half of 2023, it looked like their internal TCE program would be their main value driver. But given the breadth of possible applications, they continued to survey conferences and results in other therapeutic areas.
One of these areas was neuroscience. Since the start of the company, the team had considered developing approaches to solve the challenge of shuttling biologics across the blood-brain barrier (BBB). While the clinical relevance was clear, it felt like a daunting technical challenge. And the time and cost associated with proving efficacy for a complex neurological disease felt intractable for an early-stage startup.
So the idea was relegated to the “blue skies opportunities” list. They ran a few screens, but it was a lower priority project.
In the Fall of 2023, this all started to change
In October of that year, Lofgren headed to the Logan Airport. He was on his way to the Oligonucleotide Therapeutics Society (OTS) conference in Barcelona. At the airport, Lofgren called Kuznetsov. He wasn’t sure it was worth the trip to Europe when the Clinical Trials in Alzheimer’s Disease (CTAD) conference was taking place in their backyard in Boston.
Ultimately, he decided to go. In Barcelona, Lofgren saw extraordinary data. It felt like the oligonucleotide therapy field was in the midst of a neuroscience renaissance. Multiple companies demonstrated the ability for these genetic medicines to precisely knock down a whole slew of challenging neurological drug targets deep in the brain.
In the clinical session, Kirk Brown presented some of the early Phase 1 data for Alnylam’s ALN-APP program, which aims to wipe out the precursor protein that accumulates into amyloid beta (Aβ) plaques in Alzheimer’s disease.
But all of this exciting progress felt rate-limited by a central bottleneck: the ability to deliver the oligonucleotides to the brain. Dosing required intrathecal administration, which involves a lumbar puncture to deliver the medicine directly into the cerebrospinal fluid, bypassing the BBB altogether.
Denali Therapeutics presented early pre-clinical data on their approach to solve this problem. By targeting the transferrin receptor (TfR), they showed an early proof-of-concept that oligonucleotides might be able to be delivered into the bloodstream before being shuttled across the BBB.
While the result was exciting, the technology was still very raw. Lofgren got excited by the prospect that Manifold could do much better. If they could, it would unlock all of these exciting neurological applications of oligonucleotides.
Back in Boston, Lofgren caught up on the results from CTAD. It turned out that Roche had delivered a major BBB advance of their own. Using a similar TfR delivery mechanism, their Aβ-targeting antibody called trontinemab had been able to make its way across the BBB.
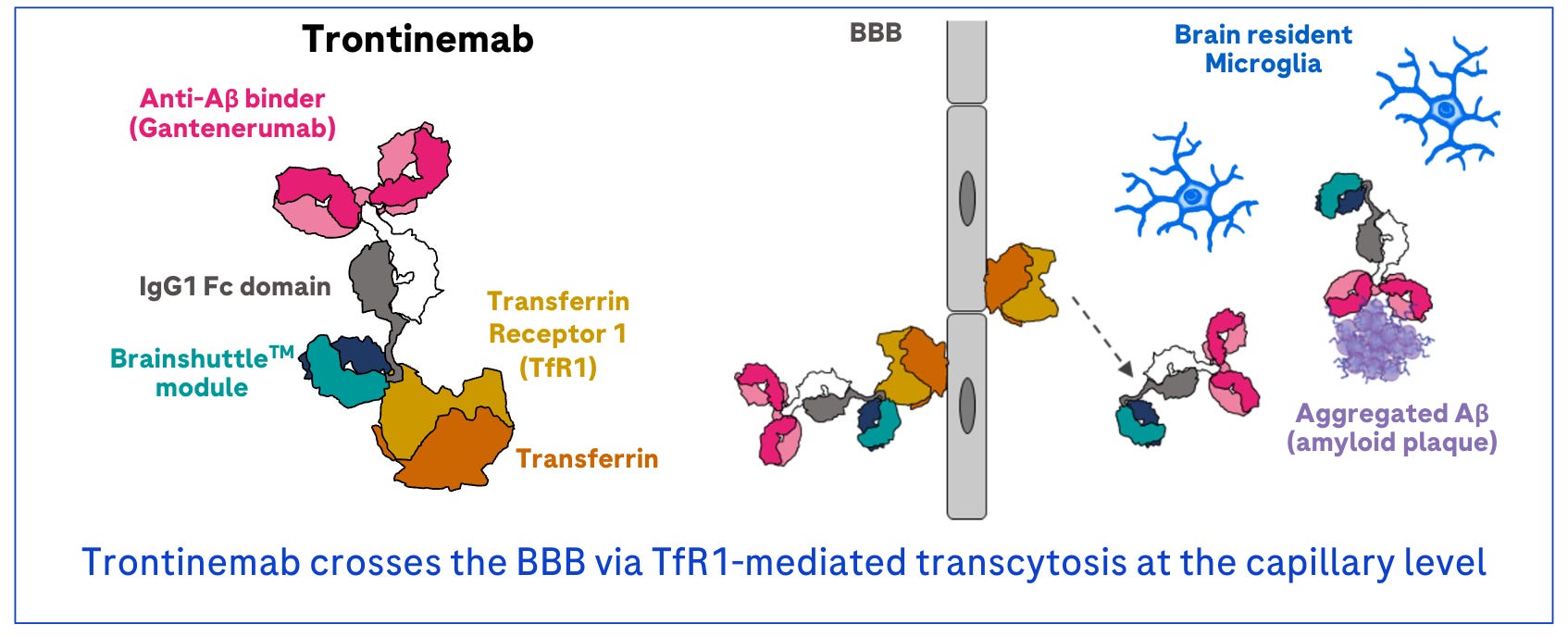
{kind=link}
Crucially, the design of the clinical study was uniquely tractable. In an interim analysis of only 44 patients, Roche had demonstrated impressive clearance of Aβ plaques using a simple PET scan. As Kuznetsov discussed the trontinemab results with people in other pharma organizations, they told him that their “jaws had dropped” upon seeing the data.
Suddenly, it felt that their BBB program was no longer just a “blue skies opportunity,” it was a chance to quickly become leaders on a new frontier.
If they could use their platform to produce better and more specific BBB shuttles, it would be possible for them to run a trial to prove that it worked. And compared to the white hot TCE space, there were far fewer competitors. The Manifold team quickly assembled the case to pivot their internal focus in this direction and presented it to their board.
Assuming the equity markets might not recover, Manifold realized that they might not be able to raise more money to keep building technology. This would mean they may have to “collapse their platform” and make a “bet the company” decision on advancing a single lead program with the highest possible value. It seemed like a BBB shuttle was the best bet to make. Their board agreed.
Even in the worst case scenario, their platform provided an incredible advantage. A massive wave of opportunity for brain shuttle technology was starting to crest. And they were in the water with a powerful surf board that could be pointed in that direction.
Manifold started to paddle furiously. Over the next year, they iterated through tens of thousands of shuttle designs, testing each molecule in vivo. Each time, they stared at a cross section of the brain, expectantly looking for a signal.
And the signal got brighter and brighter.
Several months in, they already had impressive results in mice. Some of their designs displayed an overwhelming ability to permeate the brain.
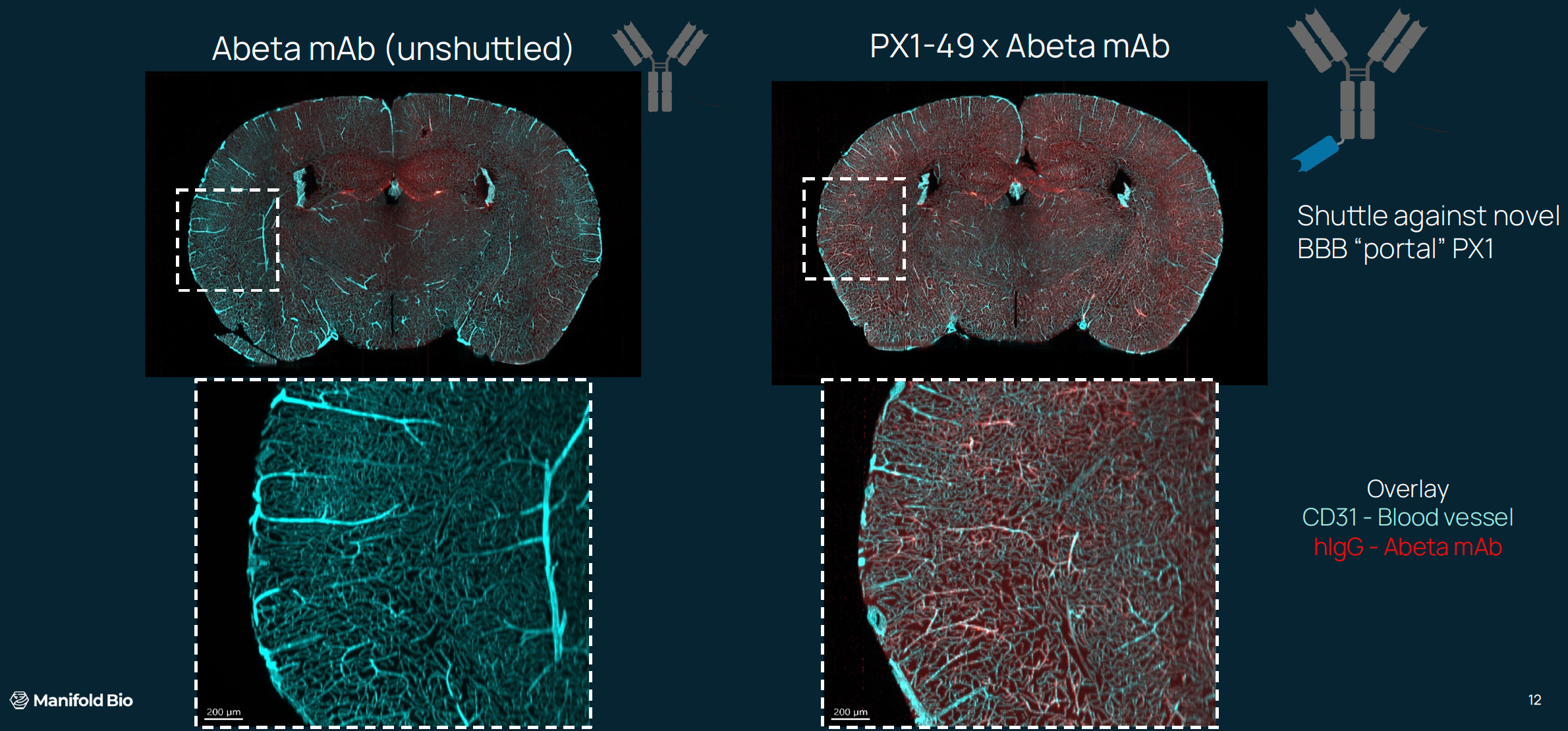
Crucially, these findings also held up in non-human primate studies—which were of course multiplexed as well. They were well on their way to having their own brain shuttles!
Towards the end of 2024, it became increasingly clear that their BBB pivot was the right bet. In October that year, AbbVie acquired Aliada Therapeutics, a startup developing brain shuttles against TfR and CD98, for $1.4B. The company hadn’t even completed their Phase 1 trial.
The data and commercial opportunity were compelling enough for an expert to vote with her feet. After two decades leading neuroscience discovery projects across Genentech, Denali, and Cajal Neuroscience, Kimberly Scearce-Levie has seen a lot of promising early findings. But Manifold’s data package stood out.
Having been involved in the development of the first TfR shuttles at Denali, she was particularly impressed by how rapidly Manifold had validated totally new shuttle targets beyond TfR. It seemed like they were really on to something.
Like Lofgren, Scearce-Levie evaluated the opportunity in front of her. Both the team and the platform seemed exceptional. And they could certainly benefit from her clinical development experience. So she agreed to join Manifold as their CSO at the start of 2025.
With wind in their sails as the BBB delivery space heated up, Manifold continued advancing their BD and partnering discussions. While the equity markets remained challenging, pharma deals were still happening. And it was becoming clear that any organization with a meaningful neuroscience pipeline would want to gain access to the new wave of brain shuttles being developed.
In lock step with Holtzman, they developed a framework for the types of deals they wanted to strike. Being an engineer, Kuznetsov describes the space of possible partnerships as an n-by-n array. Along one dimension, there are Manifold’s distinct delivery shuttles. On the other dimension, there are the possible payloads being delivered.
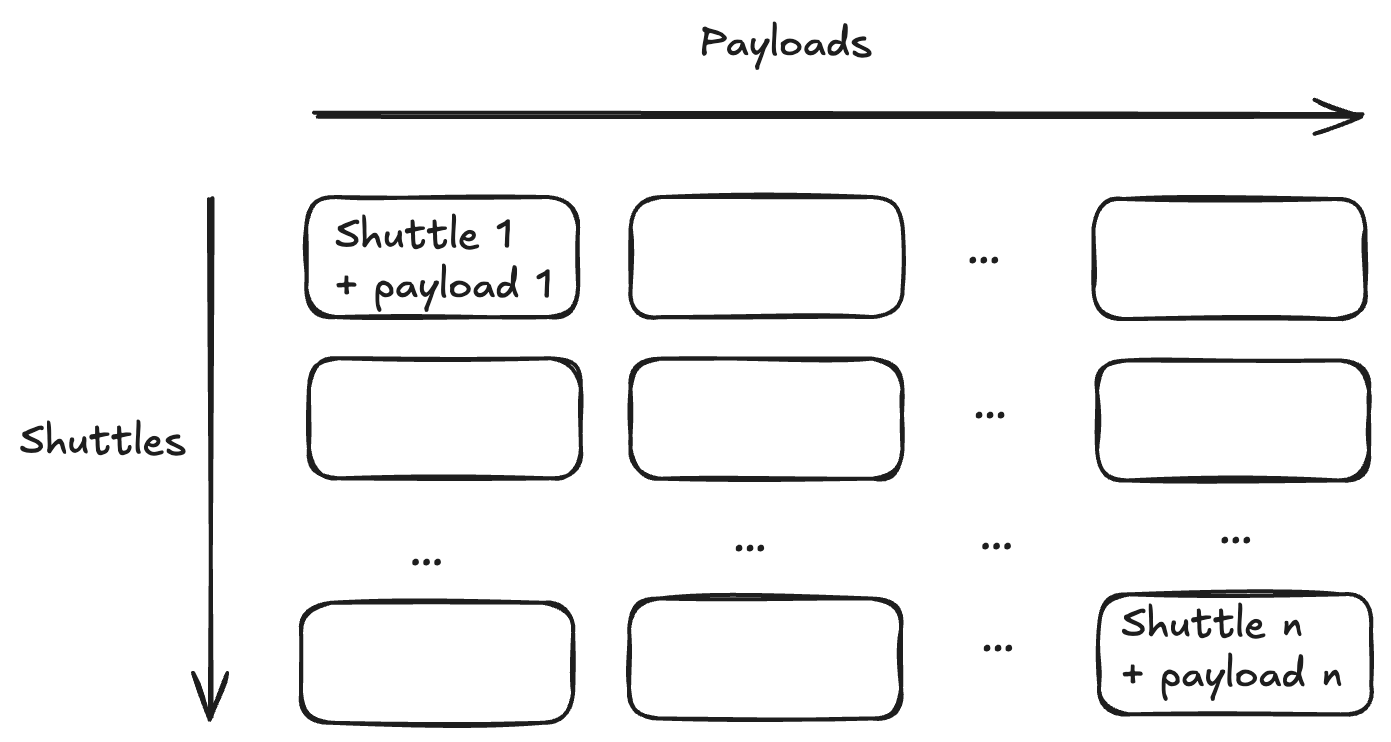
The entirety of the array represents the possible value that Manifold can create. As a platform company, they have two primary options to fuel that value creation. They can sell equity to invest in internal development for a given cell in the array. This comes at the cost of equity dilution. Alternatively, they can sell the future rights to part of the array to a pharma partner in exchange for non-dilutive capital and resources. But this comes at the cost of asset dilution.
This is the fundamental platform dilemma. Selling too much equity can collapse future value. But selling too much future asset value does the same. The two need to be carefully balanced and titrated—like hands at ten and two steering a wheel—in order to realize the greatest potential.
Consider Manifold’s options. Assume they have developed a fantastic brain shuttle. One option would be to raise a large amount of equity capital to advance this asset as far as possible with one payload. Let’s say it works. Maybe they get bought. This could be an enormous win for patients, founders, and investors.
But what about the rest of the array? Or all of the technology that was developed?
Probably never realized.
Alternatively, imagine that they license their brain shuttle IP to a pharma partner. After negotiating, they sell >90% of the future value for use of the shuttle with any payload in any indication. In exchange, they get tens of millions of dollars in cash, some milestones, and maybe some royalties if the drug makes it to market in the future. Success would be decoupled from one program and they could reinvest in the platform. But the company would be a lot less valuable as soon as the deal closed.
This deal structure would be the equivalent to selling an entire column in Manifold’s value array.
Instead of doing this, Manifold pursues deals that transact on cells in the array.
They aim to partner with pharma companies on the use of their shuttle for specific therapeutic payloads, ideally for specific indications as well (which would be a third dimension in the array). This makes for a much better deal. Pharma partners still get access to the shuttles that Manifold has developed. And Manifold still gets non-dilutive capital to reinvest in their platform while retaining the ability to use their shuttle for their own internal programs.
As they advance these conversations, Manifold can see a future where their full platform vision remains intact. Rather than betting everything on their first brain shuttles, they could soon have the resources to start meaningfully advancing shuttles for other tissues.
One exciting opportunity with compelling early data is targeted delivery of medicines to fat cells (adipose tissue). After the advent of GLP-1s, the field of metabolic drug discovery has come roaring to life. This could be another massive wave that Manifold is uniquely prepared to surf with their platform.
Over time, Manifold aims to strategically balance deal making with equity fundraising, driving forward high conviction internal and partnered drug programs using their growing suite of tissue-specific delivery shuttles.
One question in the back of Kuznetsov’s mind is if there is another possible type of deal on the table for Manifold. Historically, Big Pharma has been the sole party interested in transacting with early-stage biotech startups. But as the worlds of AI and biology converge, Big Tech is now in the mix.
For example, NVIDIA, which is now larger than all of the top twenty pharma companies combined, has made major investments in digital biology. As the technology hyperscalers aim to offer new digital biology products, Manifold’s exponentially growing proprietary in vivo dataset could gain more value in its own right.
Historically, biological data has had a short half life. New measurement tools are constantly being developed and scaled. As Holtzman has argued, “The history of data in the biopharmaceutical industry is the history of its commoditization.” Just think about the latest bids for 23andMe. Regeneron’s original winning bid in bankruptcy court for a genetic data set of three million people was $256M. To produce this data set, 23andMe had raised roughly a billion dollars and was once valued at over $6B.
But in an AI-centric world, will this change? Meta’s $14.8B quasi-acquisition of Scale AI shows the premium afforded to businesses with large corpuses of data specifically designed and captured for the purpose of model training.
In this new world order, Manifold is exploring data-centric collaborations with Big Tech in addition to asset-centric collaborations with Big Pharma.
Being Contrarian and Right
A lot of bets that Manifold has made have paid off.
Riding the tailwind of modern genomics and synthetic biology has enabled them to produce enormous data sets.
Riding the tailwind of molecular machine learning has enabled them to generate new drug designs with incredible accuracy.9
Their bet on protein multiplexing has also paid off in spades. What started as a back-of-napkin idea has scaled from tens, to hundreds, to thousands, to tens of thousands, to over one hundred thousand proteins that can be detected in parallel in vivo.
ML² sits at the intersection of two exponentially improving technologies that people believe strongly in.
In other words, it is becoming consensus.
But arguably the core bet of Manifold, which is to point these technologies at in vivo drug testing, is not.
Let’s revisit the very beginning of our story. Rather than becoming more efficient with new technologies, drug discovery is becoming more expensive—and exponentially so. Understandably, people want to figure out why.
Mice seem like a potential culprit. It’s well known that many drugs that look promising in mouse experiments end up failing in human clinical trials. The best laid plans of mice and men often go awry.
And the methodology just feels outdated. As Alex Telford traced in an essay on the origins of lab mice, the initial choice of this model organism and its subsequent proliferation throughout biomedical research had many points of random path dependency.
Telford writes, “This raises a question: what is the purpose of biomedical science? Because if it’s to efficiently discover new drugs, our investment in the enterprise of mouse models leaves much to be desired.”
A growing body of research aims to develop new approach methods (NAMs) and non-animal technologies (NATs) to ultimately replace animal testing. The year is 2025. Shouldn’t we be using AI or bioengineered models of human organs?
In the chaos of the new FDA, this viewpoint has escalated to the policy level, too. Earlier this year, the administration published a news release stating “a groundbreaking step to advance public health by replacing animal testing in the development of monoclonal antibody therapies and other drugs with more effective, human-relevant methods.”
To be clear, animal research is still the gold standard in drug discovery. Part of Telford’s argument is against mice as a model rather than animal studies altogether. But it’s a question of where people are laying down investment for the future. After the FDA’s announcement, public market investors punished Charles River Labs—one of the largest providers of animal testing services—based on a belief that animal studies will become a smaller part of biomedical research over time.
I asked Kuznetsov about all of this. He reframed it with another question. Peter Thiel, one of Silicon Valley’s most successful investors, believes that the biggest ideas are often contrarian before they gain acceptance. One of his famous interview questions is: “What important truth do very few people agree with you on?”
Kuznetsov firmly believes that biotech investors—having been burned many times by translational failures—have become overly pessimistic about the value of pre-clinical models.
The problem isn’t the animals. It’s that the models are treated as a gating filter at the very end of discovery. But what if you are able to pull these models earlier in discovery and iterate based on data from living systems? This can lead to a fundamental step change in the translational quality of the molecule—especially if this iteration is based on more advanced models like non-human primates.
In Scannell’s original paper on declining R&D efficiency, he made an interesting observation: “In the 1950s and 1960s, initial screening was typically performed in animals, not in vitro or in silico, and drug candidates were given in early stages of the development process to a range of physicians.”
In the heyday of drug discovery, screening started in animals—much like Manifold does now.10 But Manifold’s thesis isn’t just predicated on a historical observation. It’s also about picking the strategy with the highest predictive validity for the problem they are trying to solve.
It’s very possible that certain pre-clinical animal models should be augmented or ultimately replaced by new technologies. At Amplify, we strongly believe that Axiom’s approach to model human liver toxicity with AI will help reduce trial failures. And there are likely many other problems with this shape.
But for designing tissue-targeting medicines in the discovery phase, animal studies can be extraordinarily useful.
The story of Trontinemab—Roche’s brain-shuttling antibody—provides a compelling example of this. Early research was done in mice and dose-finding studies were done in primates. Rather than failing to translate, the plaque clearance observed at even the lowest doses vastly exceeded expectations. The drug worked even better in humans than it did in animals!
Manifold’s bet is that like the brain, our most predictive model for finding new tissue-targeting medicines will be mouse and monkey studies. You simply need to be able to see where a molecule traffics in a living organism. But with ML², we can increase the amount learned from each experiment by several orders of magnitude.
This will lead to much better molecules and also reduce the number and size of animal studies required to make them.
Of course, Manifold doesn’t just want to build a better mouse trap, so to speak. The driving question the founders ask themselves is: “What model has the greatest predictive validity for our molecule?” At the outset, they scaled their ML² platform with mice. At this point, non-human primates are becoming their primary model for their multiplexed experiments.
In the future, the founders wonder if they can integrate their compounding in vivo data set with other layers of information that can be generated with NAMs and NATs. As their “in vivo world model” continues to become more predictive, this could be the type of AI that helps realize a future where the behavior of a drug in the body can be accurately simulated.
So, that’s the thesis. Returning to Thiel’s belief in contrarianism, it’s not enough just to believe something others don’t. You also have to be right.
Let’s imagine what the future looks like if Manifold is right.
Their first brain shuttle is a major success. Paired with a thoughtful partnering strategy, they are able to capture value while reinvesting in the next wave of shuttles for additional tissues. It becomes increasingly clear that they have built a world-class platform for targeted delivery of both biologics and nucleic acid medicines.
This would be huge. Alnylam, the iconic biotech that’s helped unlock the siRNA modality, has built an enduring $60B business on the ability to precisely target a single organ: the liver.
What would the future of drug discovery look like if we could precisely engineer the delivery of these programmable medicines to any tissue in the body?
Of course, there is a lot of work to do for Manifold where the rubber meets the road today. They’ll need to demonstrate success for their first brain shuttles in human trials and land their first major partnerships. Achieving one breakthrough—let alone repeating the process—will be no small feat.
The Manifold team knows that. Kuznetsov draws inspiration from Pixar’s story. Like the famous studio that brought leaders in computer graphics together with talented story tellers, he aspires for Manifold to be a place for the best DNA technologists, protein engineers, and drug hunters to realize the full potential of ML².
If they succeed in tackling the bottleneck of tissue-targeted delivery, they could cement another foundational step in the biotech industry’s compounding staircase.
Thanks for reading this essay on Manifold.
I’d like to thank Gleb Kuznetsov, Pierce Ogden, Shane Lofgren, George Church and Steve Holtzman for sharing their lessons and ideas with me. My hope is that this essay helps the next generation of technical founders.
If you don’t want to miss upcoming essays, you should consider subscribing for free to have them delivered to your inbox:
Until next time! 🧬
This highlights one of the unique properties of the Church Lab. Because of their prolific output and focus on technology, people like Kuznetsov and Ogden self-select into the lab from a wide variety of backgrounds. It’s a bit like a “top-tier” venture capital fund that all of the most ambitious founders make sure to get in front of. This leads to a virtuous cycle of great investments that attract the next generation of founders. “We really don’t have to advertise or recruit, the best people just show up,” Church said to me.
This is a beautiful connection of ideas. Optimization algorithms used to train neural networks are also frequently explained using analogies relating to navigating steep terrain. While fitness landscapes typically represent greater fitness as a positive value, optimization is typically trying to minimize the cost or loss function, implying a search for the lowest possible point in the landscape.
The final multiple may have been even bigger. Two years later, Juno was acquired by Celgene for $9B, making the shares distributed to AbVitro investors even more valuable.
The eGenesis story is fascinating. Yang also co-founded Qihan Biotech, a Chinese company pursuing a similar approach. She ultimately left eGenesis to run Qihan full time. Since then, eGenesis has gone on to raise over $400M and demonstrate early clinical success, while Qihan has pivoted more towards CAR-T cell therapy.
You can read more about Wittrup’s view of this here. One question I’m not sure of is whether Wittrup’s argument will hold up in the fullness of time. What if molecular machine learning continues to capture real estate in early-stage discovery and even replaces experiments? It seems possible that providing these models and the tooling needed to use them effectively could form the basis of a very large infrastructure business.
Why does this matter? Because any time you can convert a biological measurement problem in to a DNA sequencing problem, you can ride the insane cost and scale advantages of modern sequencing technologies.
For more on terminology, Lucas Harrington recently wrote a great Practical Guide to Biotech Partnerships outlining some of the different types of partnering constructs.
Manifold will have a lot more to share on their protein design work very soon.
This is an interesting pattern that has shown up multiple times. Recursion’s main thesis early on was to reimagine phenotypic screening with new technology. Phenotypic screening produced some great drugs in the past but was gradually replaced with other approaches. Similarly, Enveda aims to revive natural product drug discovery with modern tools. Manifold is making a similar bet with animal testing.
Terrific story. The only potential warning would be to avoid emulating a company such as Sangamo which possesses some very interesting bbb technology but has yet to commercialise a single drug (and is valued accordingly). At some point companies have to prioritise and bite the proverbial bullet.
Absolutely love this. Sorry it took me so long to digest it. My backlog was a bit insane, but keep bringing the value, Elliot. This is top stuff.