
New tools for programming biology
Continuous mutagenesis, RNA writing, and more

Welcome to The Century of Biology! This newsletter explores data, companies, and ideas from the frontier of biology. You can subscribe for free to have the next post delivered to your inbox:
Enjoy! 🧬

In June of 2012, a research paper describing the discovery of CRISPR landed in Science Magazine.
In November of 2023, a CRISPR-based cell therapy for blood disorders called Casgevy gained regulatory approval.
Taken in context, this is extraordinary. Most new drugs take between ten and fifteen years to make their way onto the market. This is the time estimate for drug modalities that we have many decades of experience developing—biologics and small molecules. Eleven years ago, CRISPR was a purely academic result in bacterial cells. It was a promising result, for sure, but nowhere near a drug.
Having evolved as a bacterial immune system against viruses, CRISPR can make programmed breaks in DNA—breaks that happen at a specific sequence in the genome. From the outset, it was clear that this type of system had huge potential. If we could supply the repair materials at the site of the break, we could controllably introduce new genetic changes into living cells. A world of programmable gene editing seemed to be on the horizon, but you still had to squint to see it.
The magnitude of the opportunity—again, programmable gene editing—was matched by the magnitude of academic and commercial interest.
The 2012 Science paper has now been cited over 10,000 times, indicating the escalation in follow-up research studies. Jennifer Doudna and Emmanuelle Charpentier were awarded the 2020 Nobel Prize for their initial discovery. All of this progress has sparked a long and complicated patent battle over commercial rights to CRISPR gene editing. DLA Piper estimated that there are now over 11,000 patent families covering CRISPR-related applications.
Commercially, venture capitalists invested over a billion dollars into CRISPR startups in 2021 alone, with many leading researchers founding competing companies. All of this research and investment explains the dramatically compressed timeline from proof-of-concept to life-changing clinical product.1
But what’s unusual about CRISPR isn’t just the speed to the clinic. It’s the type of discovery that is clearly the root of an entire technology tree, rather than a standalone tool for gene editing. A programmable system for targeting nucleic acids is a general purpose tool for engineering biology.
These types of general purpose tools build on each other. The biotechnology industry owes its origin to recombinant DNA technology. It’s impossible to imagine modern genomics without PCR. Now, with these tools in our toolkit, the pace of exploration of the CRISPR tech tree is hard to even keep up with.
At its core, CRISPR is an enzyme system that is guided by RNA. Change the guide RNA, and you’ve programmed the enzyme to target another sequence of nucleic acids. The first application was for programmed DNA breaks via the Cas9 enzyme—opening the door for a modification to be made.

Very quickly, people figured out additional ways to use this system. Refinements were made to avoid the need for making DNA cuts to make edits.2 The discovery of the Cas13 enzyme made it possible to programmatically target and edit RNA in addition to DNA. The same enzymatic machinery has been adapted to interfere with genes (CRISPRi) or activate them (CRISPRa) across the entire genome.
Our toolkit for programming biology grows by the day.
Each week, new inventions are announced. The past few weeks have been no different. While I had a different essay in the works, I realized it might be worth coalescing my notes on some of the recent results into a shareable post.
Today, we’re going to quickly examine:
HACE — a tool for making lots of DNA edits in a targeted region of the genome
A trio of new “RNA writing” preprints (RESPLICE, PRECISE, CRAFT)
Bridge RNAs — “a third generation of programmable biology”
Bonus: more retrons!
Looking forward: from therapeutic modalities to therapeutic modularity
I don’t normally do research roundups like this, so if you enjoy it and want to see more of these, let me know in the comments.
Let’s jump in! 🧬
Helicase-assisted continuous editing (HACE)
In 2021, Tuuli Lappalainen and Daniel G. MacArthur wrote,
The human population, through explosive growth, has performed a comprehensive saturation mutagenesis experiment on itself. It is now the case that any single base substitution that is compatible with life is expected to be present somewhere among the nearly 8 billion living humans. Humanity has thus, in effect, done many of the natural experiments required to understand our own genotype-phenotype map; this leaves geneticists to catalog the outcomes of those experiments, and to leverage both observational and experimental approaches to understand the mechanisms by which variants alter biology.
I can’t think of a more beautiful framing for the discipline of human genetics. Natural genetic variation—every mutation present in the human population—is a massive resource for understanding the function of the genome.
Each mutation is like an experiment testing the role that a letter in the genome plays in human physiology. It’s why human genetics is a seemingly inexhaustible resource for discovering new drug targets—and why targets with genetic evidence are more likely to succeed in the clinic.
While we can catalog the outcomes of these experiments through sequencing the human population, it also helps to be able to generate and test genetic variants in the lab. A new preprint led by Dawn Chen and Zeyu Chen from the Bernstein and Chen labs introduced a CRISPR-based tool for creating targeted genetic variation in cells.
The technology is called HACE, and here’s how it works:
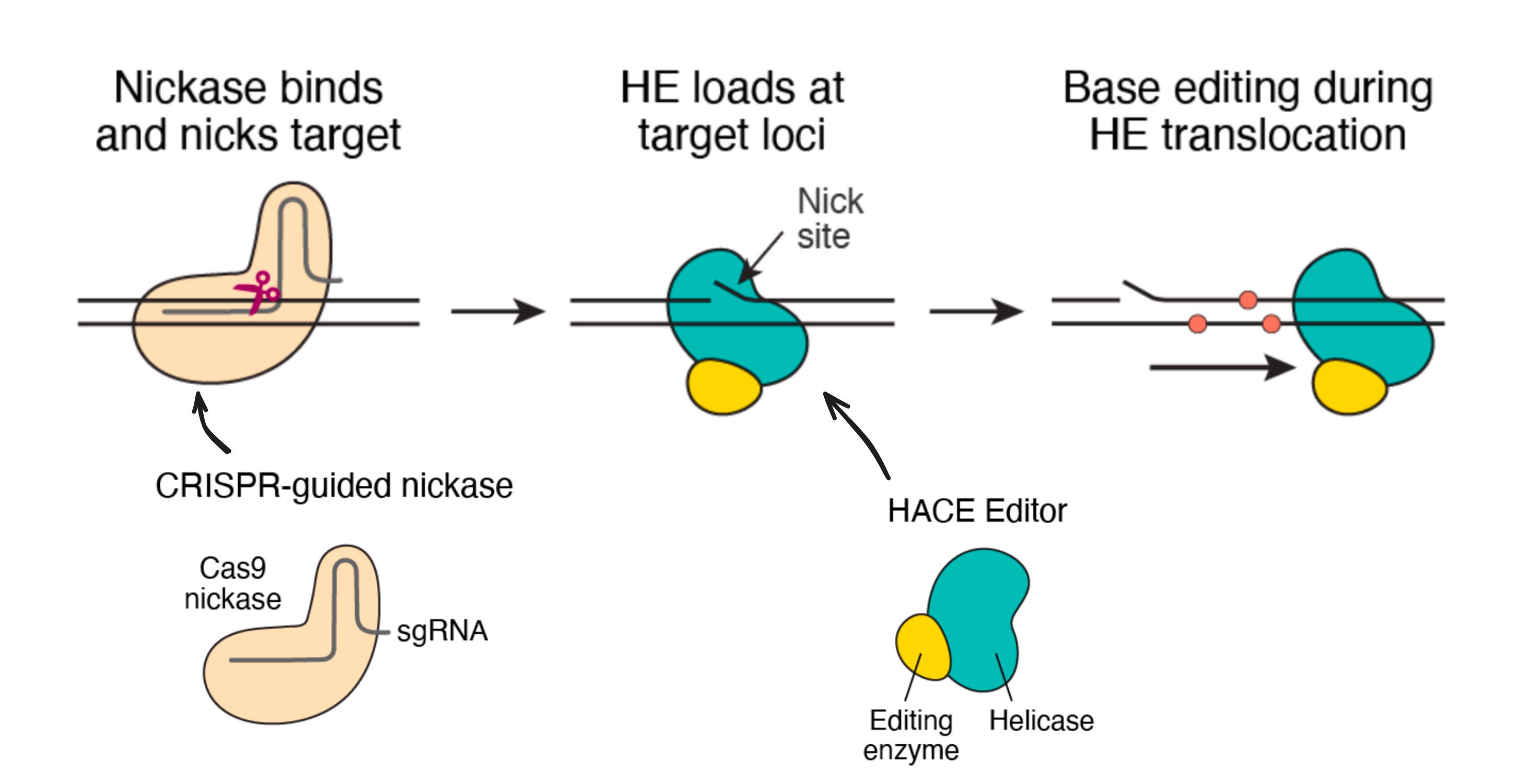
The programmable component is a variant of Cas9 that make DNA nicks—single-stranded breaks—instead of full-fledged double-stranded breaks. The guide RNA (sgRNA) recruits this enzyme to a specific sequence in the genome where the nick is made.
The second component is the HACE editor, which is a fusion of a helicase enzyme that traverses DNA, and a base editing enzyme. The HACE enzyme loads onto the site of the nick, and drags the base editor along the genome making new mutations as it goes.
The result is something like this:

A sprinkling of new genetic variation at a programmed target position in the genome. Obviously, you don’t want to do this inside of a patient’s cells. But given the power of genetic variation for deciphering function, it seems like a powerful new research tool for functional genomics.
In this initial study, the authors used this tool to drill into mechanisms of drug resistance, RNA splicing, and the role of genetic variation in the immune system. I’m excited to see what else this will be used for in the future.
It’s a great example of how CRISPR is a general purpose tool with many possible uses.
Advances in RNA writing
The first wave of CRISPR technologies focused on making permanent changes to the genome—editing DNA. As we saw with the discovery of the Cas13 enzyme, some focus has shifted towards targeting and editing RNA.
This is interesting for several reasons.
From a therapeutic perspective, genetic diseases may be treated the most effectively by a permanent DNA edit. Consider Casgevy—the first approved CRISPR-based product. Permanent genome edits are made to a patient’s blood cells, fixing the mutation that causes their sickle shape.
But not every disease has this clear of a genetic basis. In many cases, it makes sense to introduce an intervention that is temporary rather than permanent. Technologies for “transcriptome engineering”—editing many RNA transcripts in cells—could deliver this type of effect, without the concerns around making on-target or off-target edits that persist indefinitely in the genome.
Over the span of one week, three new tools were introduced describing new approaches to RNA writing.
On January 30th, the Hsu and Konermann labs—the two founding groups of the recently formed Arc Institute—published a preprint describing a tool for “rewriting human [RNA] transcripts” via trans-splicing.3
Briefly revisiting the central dogma, a DNA-encoded gene is transcribed as an RNA, before being translated into a protein product. In between transcription and translation is the wild world of RNA splicing, where RNA molecules are chopped up and pre-processed. As the authors put it, “Splicing is a fundamental biological process that plays an important regulatory role at the midpoint of the central dogma of molecular biology, enabling the same genetic sequence to give rise to a dynamic set of protein isoforms that can have distinct biological functions, subcellular localizations, or stabilities.”
Normally, this happens in cis—meaning all the splicing is done to one RNA molecule. In very rare cases, two distinct RNA molecules can be spliced together. This is called trans-splicing.
In this study, the authors invented a system for programmatically controlling trans-splicing using CRISPR machinery:

This technology, called RESPLICE, has two modules.
The first module is somewhat complex. It’s a variant of Cas13 (CasRx) that is catalytically inactive—meaning it binds but doesn’t cut RNA. The guide RNA brings along a new exon to be spliced in. This is called the trans-splicing module (TSM).
The second module is a catalytically active CRISPR enzyme (Cas7-11) that is used to cleave the RNA transcript downstream of where the new exon is supposed to be added. This two module design reflects the fact that to get this to work, you need to:
Create proximity between the exons you want to be spliced together
Outcompete the normal splicing product the cell is trying to produce.
So, what could this tool be used for? It could be used to “replace disease-causing exons, repair truncated proteins, or engineer protein fusions.” Again, engineering the transcriptome of a cell rather than the genome should have uses in both medicine and engineering.
This broad utility explains why the labs at the Arc weren’t alone in their efforts to get this to work.
On February 1st, the Abudayyeh-Gootenberg Lab at MIT published their own preprint describing the independent development of a technology for programming trans-splicing called PRECISE
Here, all the logic is similar, but the system relies on RNA hybridization instead of Cas13 to bring the new exon into proximity of the molecule being edited. The same enzyme (Cas7-11) is used to cleave the unwanted exons.

After getting this to work, the authors explored ways to program new splicing events without CRISPR. While CRISPR is powerful, introducing foreign bacterial proteins into the body comes with the risk of triggering an immune response, and their size can make therapeutic delivery tricky. To do this, they used ribozymes, which are RNA molecules that can catalyze enzymatic reactions.

But the excitement around trans-splicing doesn’t stop there.
On February 8th, the Asokan Lab at Duke University published their own preprint describing a CRISPR-based system for trans-splicing.
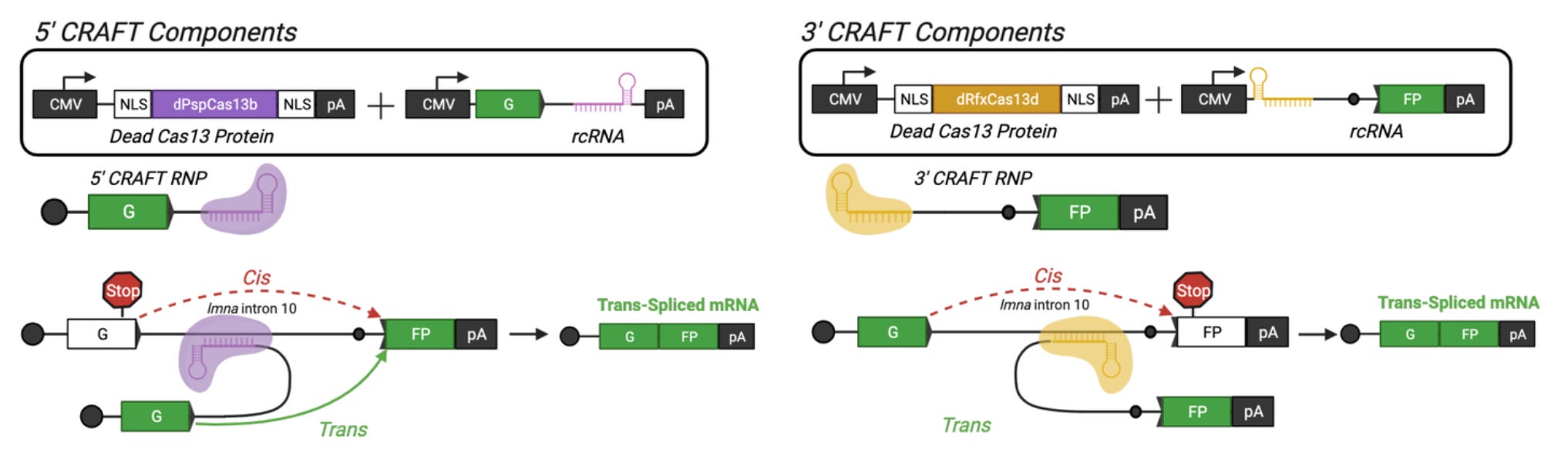
The logic is very similar: an RNA-targeting Cas13 enzyme is used to stitch exons coming from distinct RNA molecules together.
This trio of new studies highlights the growing importance of preprints. It’s encouraging to see scientists gain more control over their own publishing timelines. Instead of feeling “scooped,” or having editors potentially reject some of this work based on primacy, we’re seeing a full-on RNA writing bake off.
Science gets to move at the speed of the Internet. These methods will be tested in labs around the world and refined. The most compelling ideas will be mixed and matched, and we’ll have improved tools as a result.
It was the kind of week that made one RNA biologist say, “this is nearly as important as the first reports on CRISPR/ Cas9.”
RNA writing is a space worth watching closely. Two companies—Wave Life Sciences and Ascidian Therapeutics—are already preparing to test RNA editing medicines in the clinic. Another company, Amber Bio, emerged from stealth to commercialize their own recently published Splice Editing technology.
It’s exciting to see the progress in genome engineering spilling over into our ability to engineer the transcriptome. Hopefully patients benefit from these tools in the coming years.
Bridge RNAs
Bioengineering is a strange discipline. CRISPR wasn’t invented. It was discovered.
A lot of brilliant engineering was required to shape it into a reliable gene editing tool, and ultimately a medicine. But this key insight is important: powerful tools for programming biology are buried in genetic databases just waiting to be found.
A week before publishing the RESPLICE preprint the Hsu Lab at the Arc Institute shared a “detective story” that led to the discovery of a new system called bridge RNAs.
The group hunted through a massive bacterial database looking for a family (IS110) of mobile genetic elements (MGEs). MGEs, sometimes referring to as “jumping genes,” are stretches of DNA that paste and cut themselves in and out of the genome.

By carefully analyzing the flanking non-coding regions of this MGE family, they found something crazy. These stretches encode a set of RNA molecules—what they now call bridge RNAs—that contain hairpin loops that recognize target and donor DNA sequences.

Not only are they likely a critical part of how these elements pop in and out of the genome, they showed that they are capable of programming the removal, addition, and flipping of DNA sequences.
These are all fundamental operations for engineering DNA.
It’s still early, but these bridge RNAs may prove to expand the genome engineering toolkit—making it possible to mix, match, and rearrange large segments of DNA programmatically.
It’s remarkable to think about what other tools might be lurking in these databases.
Bonus: more retrons!
Speaking of genome editing tools hiding in plain sight, let’s briefly turn our attention to retrons. Like CRISPR, retrons are a type of bacterial immune system that have evolved to detect viral infection.
Retrons highlight how wild molecular warfare between bacteria and viruses can be.
Retrons are genetically encoded in bacteria. The system consists of a non-coding RNA molecule that gets expressed. Sitting in the same operon, there is a reverse transcriptase enzyme that produces a copious volume of single-stranded DNA molecules—the retrons—by transcribing the RNA molecule back into DNA. It’s currently understood that viruses chop up these molecules, which produces a toxic byproduct that serves as a suicide switch for the host cell. When the cell dies, the phage is unable to reproduce and neighboring cells are spared from infection.
From a technological perspective, retrons are a useful tool for producing abundant single-stranded DNA inside of cells. This DNA can serve as a template for genome engineering. Instead of needing to add a repair template for CRISPR (or something like bridge RNA), it can be made directly inside the cell using retrons.4
The Shipman Lab at UCSF is one of the groups most actively researching retrons, and I’ve been excited about their work for quite a while. In a preprint posted last month, they conducted the most extensive experimental characterization of retrons to date.

There are thousands of computational predictions for retron sequences, but few have been tested in the lab before. This study developed an experimental approach to test over a hundred new retrons experimentally.
If you’ve been reading CoB for some time, you may know what I’m thinking: this is a beautiful example of the 4-S model at work. Modern DNA Sequencing made it possible to sequence hundreds of thousands of genomes. Software tools were used to make functional predictions. Now, DNA Synthesis tested these predictions at an unprecedented Scale.
This census will likely be a gold mine for future retron engineering. Already, it appears to have uncovered several substantially more efficient new retrons.
While they haven’t yet become a standard part of the genome engineering toolbox like CRISPR, more detailed work like this could establish retrons as an important tool for programmable DNA production in cells.
Looking forward: from therapeutic modalities to therapeutic modularity
We’ve just covered a lot of ground. A lot of new acronyms and molecular mechanisms.
Let’s look at one more set of new results that helps frame where all of this might be going.
On February 1st, Intellia Therapeutics published new clinical results for CRISPR editing of the liver to treat hereditary angioedema—a rare disease where patients suffer from “angioedema attacks” of severe swelling and fluid accumulation, most often in the limbs, face, intestinal tract, and airway. So far, patients receiving the editing treatment have experienced a 95% reduction in these attacks.
Taken on their own, these trial results are impressive. But there’s another layer to this story. As Fyodor Urnov pointed out, there is only one difference between this medicine and another Intellia therapy for a completely different disease: the guide RNA.
This is what a future with programmable medicine looks like.
In biotech, we often talk about drug modalities, which are specific modes of treating disease like small molecules and antibodies. Every new tool we looked at today was published in the span of a few weeks. What does the world look like in a decade? Two decades? A century?
We could transition from modalities that require intensive development for every new application, to programmable modules where only the instructions need to be updated to make entirely new medicines.
This type of technology sounds like a cash printing machine. Surprisingly, nobody seems to have solved the business model problem for curing thousands of genetic diseases with CRISPR. Intellia, the company with some of the deepest expertise in this technology, had to lay off staff earlier this year.
Squaring these facts requires a consideration of the current economics of drug development. In an upcoming post, we’ll explore this in detail. Is there a platform strategy that could realize the full potential of CRISPR?
Until then, thanks for joining me on this tour of the powerful new tools for programming biology.
Thanks for reading this roundup of some of the most exciting advances in genome and transcriptome engineering.
If you don’t want to miss upcoming essays, you should consider subscribing for free to have them delivered to your inbox:
Until next time! 🧬
In a clinic trial for patients with sickle cell disease, Casgevy was tested for its ability to prevent vaso-occlusive crisis, where misshaped blood cells block blood flow. Of the 31 patients evaluated for this endpoint, 29 (93.5%) had no vaso-occlusive events for at least a year.
Two major results here are the introduction of base editing in 2017, and prime editing in 2019 from the Liu Lab.
There’s been a lot excitement around the Arc Institute—including from Paul Graham. It’s awesome to see the interest in biotech from the tech world grow.
This is just scratching the surface of what retrons could be used for. The authors point out that “the faithful production of abundant single-stranded DNA in cells by retrons has been used to produce templates for genome engineering, transcriptional receipts for molecular recorders, and transcription factor decoys.”
Enjoyed the research roundup, please do more! Thanks.
Enjoyed the research. I feel like more people are getting into the computer science or management degrees and less into bio engineering space. I may be saying this because I did CS in my undergrad and working in a software company. I have heard people like Bill Gates say that computational biology is going to be the next thing but it's not as easy as building software where you just need a laptop and some decent coding skills. I have been reading your posts for some time and I'm interested in may be exploring this space by doing some projects. How can someone like me from programming background transition to this field?