
CSHL: AI in Biology
A conference for the history books

Welcome to The Century of Biology! This newsletter explores data, companies, and ideas from the frontier of biology. You can subscribe for free to have the next post delivered to your inbox:
Today, we’re going to explore the wide range of topics covered at CSHL’s 90th Annual Symposium, which was dedicated to AI in Biology.
Enjoy! 🧬

If you wind your way through a quiet, wooded suburb outside of The City, you’ll reach a harbor. Situated on a hill overlooking the water, there is a Temple of Science. This Temple is centered around a task of the utmost importance: preserving a magical thread that connects the past, present, and future of the life sciences.
On one end, there is a gentle tug from the ghosts of Barbara McClintock, Martha Chase, and Alfred Hershey, reminding you of their elegant experiments that became part of the canon of genetics. Farther along, figures like Jim Watson grip the thread more fervently as they advocate for the centrality of their discoveries in the birth of molecular biology. If you put one hand in front of the other and continue to follow where it takes you, you’ll pass through the rise of genomics and end up on the frontier of biology.
Of course, I’m talking about Cold Spring Harbor Laboratory. For over one hundred years, this little research institute in Long Island, New York has punched well above its weight. CSHL played a critical role in multiple paradigm shifts in biology—including genetics, molecular biology, and genomics—as evidenced by the eight Nobel Prizes awarded to researchers from “The Lab” over the years. When normalizing for size, the Nature Index ranked CSHL as the most prolific biomedical research institution in the world.
I’ll never forget my first visit to The Lab. In February of 2020, I flew from Seattle to interview for the CSHL graduate school program. Famously (among researchers on the grad school interview circuit), they would arrange for each recruit to be picked up in a black car from the airport.1
The campus itself, which is a direct physical representation of the magical thread that The Lab preserves, is equally memorable. A cluster of pristinely maintained colonial buildings, each painted white, borders the water. Above them is the Upper Campus, consisting of darker, modern renditions of the same pattern. Scientific art installations—like the Waltz of the Polypeptides or a gazebo with a phage structure on the tip—can be found along the walking trails.
Over the course of three days, I hurried around The Lab for a wide range of activities, including eleven interviews with faculty—two to three times the number that most other graduate school programs typically scheduled. It was wonderful and intense.
Ultimately, I was persuaded to go west for graduate school. Thankfully, there are many reasons to continue coming back to CSHL, which has been described as “the crossroads of biology.” Each year, they host dozens of conferences and courses that draw top researchers from around the world.
But one particular conference stands out in importance. Since 1933, CSHL has hosted an annual Symposium on Quantitative Biology. Reginald Harris, who conceived of the conference, wrote that the “primary motive of the conference symposia is to consider a given biological problem from its chemical, physical and mathematical, as well as from its biological aspects.” In retrospect, this was visionary.
Over the next several decades, chemists and physicists would revolutionize the life sciences. In 1944, Erwin Schrödinger, a leading physicist, wrote What is Life?, a book exploring open questions in biology through a new lens. It inspired many researchers and students, including a young James Watson, to pursue biological research. In 1953, at the 20th annual CSHL Symposium, Watson presented the structure of DNA for the first time in public.

For obvious reasons, this gave the CSHL Symposia a sort of “mythic quality” moving forward. This reputation compounded quickly. Over the next 15 years, the pioneers of molecular genetics would travel each year to present their most important discoveries—such as the central dogma and the genetic code—at CSHL.
The tradition continues to this day. Each year, the Symposium is organized around a topic considered to represent the frontier of life sciences research.
Which brings us to the topic of the 90th Cold Spring Harbor Laboratory Symposium on Quantitative Biology: AI in Biology.
Readers of this newsletter are not strangers to the fact that AI is reshaping biology. The tools derived from breakthroughs such as AlphaFold have been adopted by seemingly all biologists at this point. But it was stunning to see these advances celebrated so prominently in this venue. It felt historical.
As Bruce Stillman, CSHL’s current President, pointed out in his opening remarks, this topic connects back to the very origin of the Symposia—as the name suggests. Harris had spotted the emergence of a new quantitative paradigm in biology. Between then and now, molecular genetics did in fact transform biology into an information science.2
It’s becoming more clear each day that the next chapter of this story is AI. Sydney Brenner, one of the most central figures of molecular biology, gave one of the most incisive criticisms of the field in his Nobel Prize lecture: “We’re drowning in a sea of data and starving for knowledge.” AI is starting to change that equation.
For five days, top researchers in the field shared updates on their efforts to use machine learning to decipher the mechanisms of DNA, RNA, proteins, cells, tissues, organs (especially the brain), and how information flows between these different biological scales. And there were examples of how AI agents might be able to autonomously carry out some of this research—which was met with a combination of excitement and anxiety from attendees.
It was one of the most compelling conferences I’ve ever attended, so I want to share some of what I saw. Before jumping in, this requires a few quick notes on the format of the event.
First, attending a Symposium feels like drinking from a scientific firehose—by design. CSHL is truly a Temple, or maybe even a monastery. Most attendees stay on campus and don’t leave for the duration of the conference. Talks are back-to-back all day in the main auditorium, followed by communal meals and poster sessions that run throughout the evening. It’s non-stop. My goal isn’t to give an exhaustive blow-by-blow, but to highlight some of the themes and topics I found most exciting.
Second, following in the tradition of Watson, many researchers share more new and unpublished data than is typical at other conferences. To respect this tradition, I’m going to focus on the data shared that has already been published, with more high-level descriptions of new research directions and results.
With all that said, let’s get into it! 🧬
Capturing Biological Scales and Dynamics
Let’s briefly think about AlphaFold. This model was the biggest AI breakthrough in biology—and arguably all of the natural sciences—we’ve seen so far. In the opening session the first evening, Pushmeet Kohli, the VP of Science at Google DeepMind who spearheaded the project, gave some background on how AlphaFold came about.
As he humbly began his talk for “folks who had not heard of DeepMind,” (which was met with laughter) this London-based AI lab was on the hunt for hard science problems to demonstrate their capabilities. And protein folding was a perfect fit. It’s an incontrovertibly hard problem—a contest had been running for decades with scientists from around the world competing to solve it.
But it’s also a problem with several unique characteristics. First, the prediction task is clear and static. Predict the 3D structure of an amino acid sequence. Second, there is a lot of data for models to learn from.
The model’s performance was a landmark moment for the field. Now, researchers on the frontier of AI in biology are grappling with ways to develop models that capture more of biology’s most important characteristics. Biology is far from static. Proteins don’t have a singular structure, rather they are constantly shifting between multiple conformations. Biology is dynamic. And life unfolds across multiple scales that span orders of magnitude in size—from individual nucleotides all the way up to complex tissues, organs, and ultimately organisms.
The Symposium was organized into sessions on different research frontiers. This theme of capturing the dynamical and multi-scale nature of living systems cut across each one.
One of the early sessions focused on AI models for genome regulation. Žiga Avsec, who leads the genomics initiative at DeepMind, presented on their AlphaGenome model that was published earlier this year. This model builds on a growing body of research that links DNA sequences to functional data, such as gene expression, chromatin accessibility, or transcription factor binding.
AlphaGenome differs most dramatically from other DNA sequence-to-function models in the length of DNA it ingests, and the number of functional data types that it predicts. The model accepts one million DNA bases (1 megabase, or Mb) and predicts eleven different data modalities. This is a step towards a “foundation model” for regulatory genomics, which required a lot of clever engineering to synchronize computation across multiple GPUs.
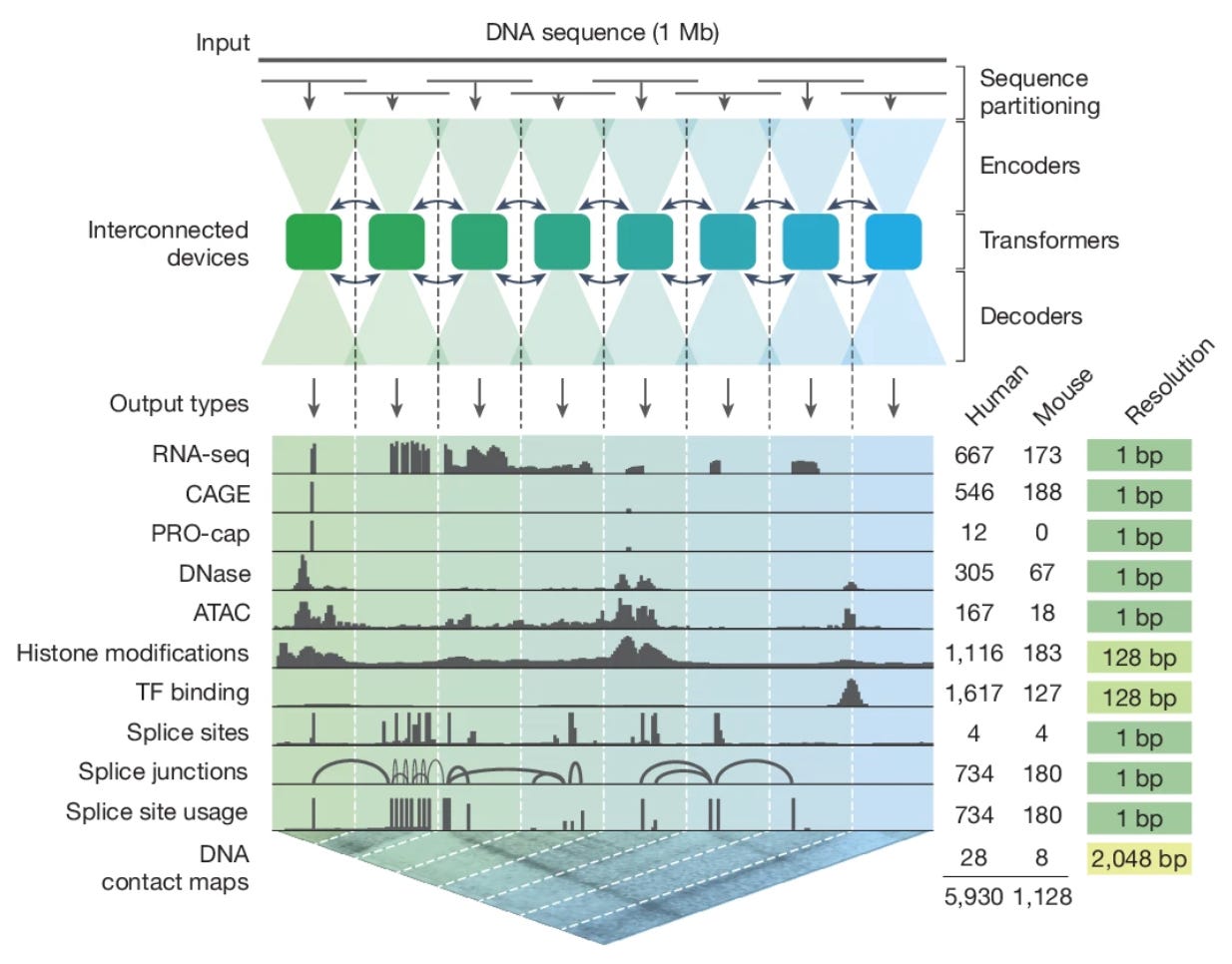
Avsec explained the motivation for AlphaGenome by talking about the multi-scale nature of genome regulation. Genes can be regulated by faraway enhancer elements, and transcription initiation involves structural changes to DNA and the intricate coordination of multiple different proteins. The power of machine learning is that it can integrate different measurements capturing these dynamics in a single unified representation.3
Jian Zhou, an assistant professor at the University of Chicago, gave a really exciting talk in this session exploring a research direction to infuse dynamics even more directly into this class of models. Instead of predicting an average measurement, Zhou proposed predicting a distribution of values for a given sequence. For example, predicting the underlying distribution of chromatin accessibility measurements for a sequence, which could reveal different dynamic states that unfold over time. This research is still developing and it will be interesting to see where it goes.
In a session on AI for studying evolution, several researchers focused on capturing a different dynamic of critical importance: the interactions between proteins. Yunha Hwang, who recently joined MIT as an assistant professor, presented on her group’s work to dramatically scale this type of prediction. In order to model protein-protein interactions across entire microbial proteomes, they developed a method called FlashPPI, which scales linearly rather than quadratically.
Hwang gave a simple explanation for a hypothetical genome with 5,000 proteins. Testing every pairwise combination would require 12.5 million calculations. But scaling linearly, getting the same answer would only require 5,000 calculations.
Using this approach, they can create maps of the interaction networks across entire microbial proteomes in minutes. And they made this technology instantly accessible via a Web platform called SeqHub. It’s worth checking out!
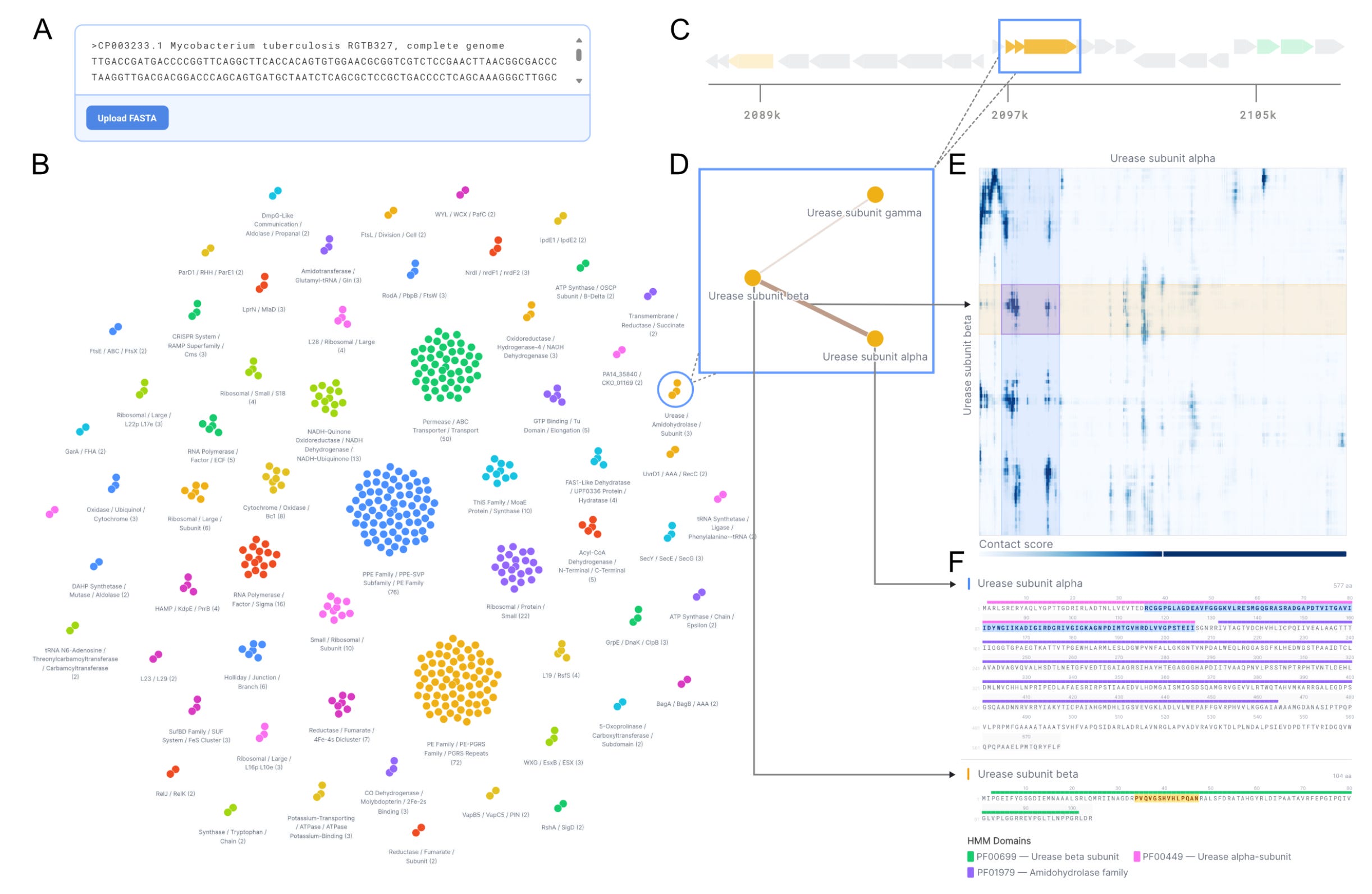
Martin Steinegger, a professor at Seoul National University, is motivated by similar problems. Over the years, he’s led development of some of the most widely used tools for structure-based protein search, such as foldseek and MMseqs2. More recently, his focus has moved from individual proteins to protein complexes. He shared updates on new tools for comparing the quaternary structures of proteins at scale, and expanding the AlphaFold Database to include 1.8 million new high-confidence predictions of protein complexes.4
Consider the types of questions that came up throughout the Symposium.
Emma Lundberg, a professor at Stanford, asked: Can we predict the sub-cellular localization of a protein from its sequence? And can we build spatial models of cells that capture information about the sub-cellular complexes they are comprised of?
Daniel Bear, the VP of AI Research at NOETIK, asked: Can we predict a cell’s gene expression based on its tissue context? And can this help us better understand how a cancer patient will respond to a drug?”
Ellen Zhong, an assistant professor at Princeton, asked: How can we decipher protein dynamics and conformational states from complex and noisy Cryo-EM data?
These are thorny and exciting problems. AlphaFold and the models in its lineage have already delivered real value (and enabled new discoveries, as we will see) for researchers around the world. Now, the goal is to move our way up the hierarchical chain of complexity. How do proteins move, talk to each other, and form complexes in cells? How do cells interact with their neighbors within tissues?
We’re just scratching the surface—which is the exciting part.
Agents, Agents, Agents
Maybe I’m in a bubble in San Francisco, but it’s hard not to constantly hear about AI agents in the year 2026. It’s strange to think, but it’s been three and a half years since ChatGPT was first released. That’s long enough for many humans to feel frustrated by the shortcomings of what was once magic. Now, we want these models to do work for us, and to carry out longer, more complex projects that require reasoning.
There are now many efforts to develop systems for “agentic science,” where AI models are able to autonomously develop new hypotheses, design experiments, and analyze results. This concept was another recurring theme at the symposium.
Pushmeet Kohli hit on this the first evening. The last third of his talk focused on DeepMind’s efforts to build an AI Co-Scientist, which they published a new paper on last month. Given a research goal by a human scientist, this system develops a research plan and then kicks off a “tournament” of agents competing to develop new hypotheses. Agents within this system have different tasks. Some are designed to “reflect” on the ideas being generated. Others are tasked with “evolving” them.
While the goal is hypothesis generation, the AI Co-Scientist itself is no longer just a hypothetical. DeepMind has already given early access to academic researchers working in a wide variety of biomedical domains. Kohli highlighted a high profile example where the Co-Scientist was able to predict a new mechanism of bacterial gene transfer before the result was published in the literature.
He played a video of the lead author’s response to the AI predictions. A BBC interviewer asks José Penadés, a professor of microbiology at ICL, what his reaction was when the AI system “when it came up with the answer in two days that it had taken you ten years to find.” Initially, Penadés couldn’t believe it. He thought that his use of Google products and Gemini must be leaking into the training set. Over time, his disbelief turned into excitement. He said that it was “not just that the top hypothesis that they provided was the right one, it was that they provided another four and all of them made sense. For one of them, we never thought about it, and we are now working on that.”
The reaction at the Symposium was fascinating. An immediate question from a graduate student in the audience was about what this meant for him and the undergraduates that he taught. Kohli responded by emphasizing that scientists will always be valuable, but that the real skill over time will be more about posing the right research questions to point these systems toward, rather than laboring by themselves on unaided hypothesis generation. Will the best scientists of the future effectively be the best prompt engineers for their AI co-scientists?
The Co-Scientist comes with the following disclaimer:
Note: Co-Scientist is intended to be a partner in research, not a replacement for scientific or clinical expertise, and users are responsible for any decisions they make using the outputs as they continue their scientific journey.
In another presentation, Marinka Zitnik, a professor at Harvard, shared some of her group’s research on agentic research systems. One of the first projects was to develop the infrastructure necessary for AI scientists to be able to leverage scientific tools—specifically the massive set of computational tools and databases that human scientists stitch together to carry out their work. This project is called ToolUniverse, and it’s freely available for use here.
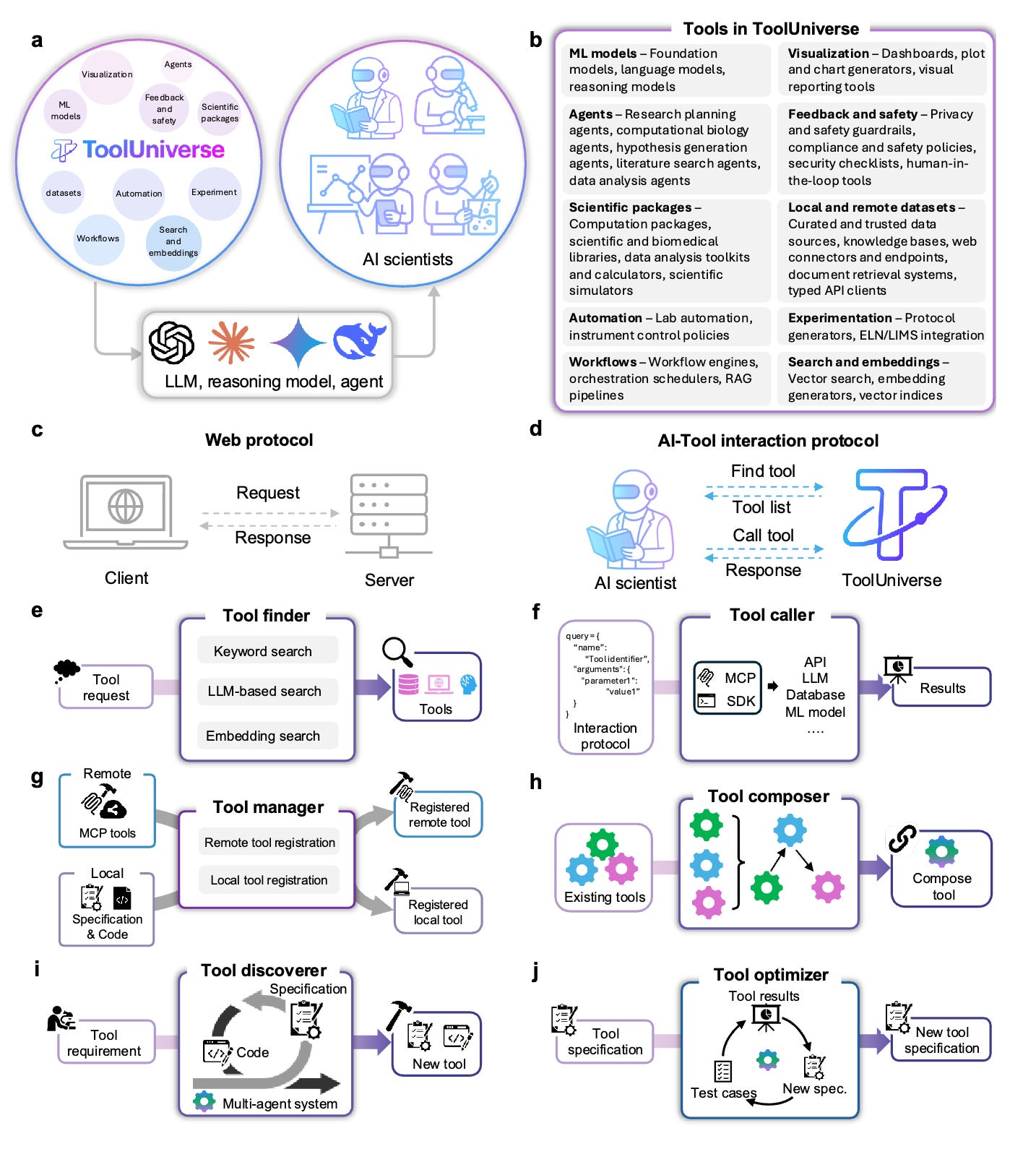
Zitnik cited some impressive usage statistics: between November and 2025 and February of 2026, ToolUniverse was used to run over 700,000 analyses. In the week before her talk, the software was installed 190,000 times! And these tools are already being used to impact patient outcomes. In a project focused on neurology, outputs from AI systems and downstream validation experiments in the lab led a physician to prescribe a repurposed drug for a bipolar patient.
In more recent work, Zitnik’s group developed a system called AutoScientists, which she described as a “self-organizing agent team for long-running scientific experimentation.” The agents can spontaneously form teams and also work independently over multiple days. In several demonstrations, this fleet of agents was able to produce new state-of-the-art models and results across multiple different scientific problems.
Of course, most domains of biological and biomedical research require experimental research, not just computational modeling. But researchers have ideas for infusing agents into the lab, too. Le Cong, a professor at Stanford, shared his group’s work on LabOS, a system consisting of software and hardware—such as smart glasses and robots—that aims to digitize lab work and make it executable by agentic systems.
While the first version is aimed at equipping human scientists with agentic co-pilots, a subsequent version in development will enable robots to carry out lab work autonomously.
There was no shortage of conversation about this tech. I’d characterize the reception as a mix of excitement, dismissiveness, and anxiety. It’s hard not to be at least a little bit excited about a vision for a very different future. However, extraordinary claims require extraordinary evidence. Scientists have dreamed of automated labs for decades, and most work is still carried about by hand. But if this does work this time, many scientists—especially younger trainees at the symposium—wondered openly about what this might mean for their careers.
Beyond the talks more directly focused on agents, this theme frequently came up towards the end of other presentations. Yunha Hwang briefly mentioned that SeqHub has an AI agent of its own. And Ellen Zhong mentioned that her group is exploring the use of agents to automate many of the cumbersome steps of Cryo-EM analysis.
I would suspect that more tools will natively offer self-driving capabilities over time. We are very early in the development of agentic systems in biology.
AI in Practice
Unlike most Symposia of the past, this was a gathering of tool builders. Despite the naming choice, many of the researchers that presented spend most of their time developing AI for biologists, rather than using AI in biological research. But there were some notable examples of how AI is being used for discovery interspersed throughout the sessions.
In fact, Jennifer Doudna kicked things off with the first presentation. She shared that “the most common question she is asked” these days is: How will AI change biological research?
Her answer started with an interesting framing. She described CRISPR as a bioinformatic discovery. This gene editing technology with transformative capabilities in research and medicine didn’t emerge from a biological hypothesis. At first, CRISPR sequences were algorithmically detected as an unusual pattern in large databases of microbial genome sequences.
In other words, computer science has already revolutionized biological research. Next she shared a few vignettes on how AI is accelerating her group’s current efforts. One project used AI models for proteins to design more compact versions of RNA-guided nucleases.
Doudna’s final vignette went full circle. Just like the original discovery of CRISPR, they went mining through genomic databases. This time, they were hunting for CRISPR’s evolutionary predecessors. And this time, their search was powered by AI. Using tools developed by researchers like Martin Steinegger, they carried out a structure-based search against the AlphaFold database.
Sifting through hundreds of millions of structures, they uncovered a new system they named Viral Interference Programmable Repeats (VIPR), which is an RNA-guided DNA recognition more ancient than CRISPR that has its own recognition code. They weren’t able to crack the code until they used a genomic language model to decipher how VIPR recognition works. (See publications here and here for more detail.)
Doudna used this story to paint a pragmatically optimistic vision for the future of AI in biology. Biology is hard. Discoveries like this still require serendipity and careful detective work. But AI is a powerful tool when guided well. As she put it, “Big biological questions will need AI-assisted scientists.”
Perhaps the most unique presentation came from Edward Buckler, a Research Geneticist at the USDA Agricultural Research Service (ARS) and professor at Cornell. At the beginning of his talk, he joked, “So… why should we care about plants? I’m the only plant guy talking here!” (This was met with applause. The vibes all week were great.)
While most biological research myopically focuses on humans, Buckler pointed out that land plants account for 80% of global biomass. He also pointed out another mind-blowing stat: using a combination of genetics and new management techniques, U.S. corn and dairy yields have increased seven-fold over the past century. This has to be one of the most under-appreciated wins for genetics!
But just like in most domains, the increasingly sophisticated genomic prediction models used in agriculture work the best for crops with large amounts of historical data. Buckler is interested in a prediction problem with a much sparser set of measurements to train on. He wants to be able to predict how roughly 2,000 critical plant species around the world will fare in a future with a substantially different climate.
To do this, his group has developed a series of AI models, including PlantCAD and PlantCAD2, that are designed to generalize across a wide range of plant species. Using these models, they analyzed how over 700 different grass species are likely to adapt to temperature changes over time, and discovered 17 genes that are likely to play a critical role in adaptation. It was exciting to see an application of AI in biology outside of biomedicine with such potential for impact.
But not all of science is done for application. In arguably the most beautiful presentation of the conference, Andrea Pauli, a Senior Group Leader at the Institute of Pathology in Vienna, gave a decisive demonstration of how AI tools can be harnessed to answer basic research questions. Pauli’s lab studies the underlying mechanisms of fertilization, which she refers to as “life’s first kiss.” Although none of us would be here without it, there are still major open questions about how this critical process works.
Generally, the shape of the problem is one of protein-protein interaction. Researchers in the field have discovered a variety of surface proteins on both sperm and egg cells that are necessary for fertilization. But it’s been very challenging to make progress on understanding how these different proteins actually interface with each other.
With the advent of tools like AlphaFold-Multimer, which predicts protein complexes, this started to change. Pauli’s lab started to run in silico experiments screening for interactions between a wide range of fertilization factors. This approach revealed a predicted trimeric complex that serves as the binding site for egg fertilization.
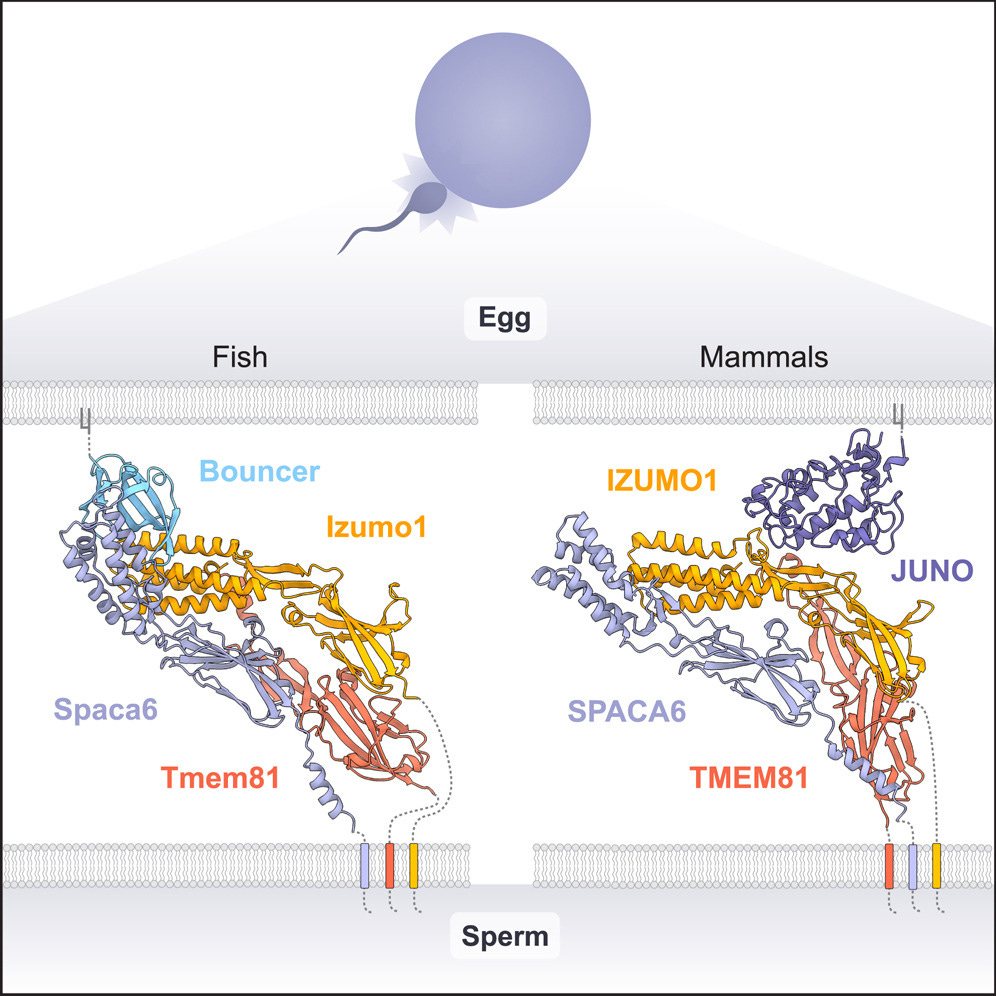
In his Nobel Prize lecture, Demis Hassabis cited this discovery as one of the most remarkable use cases of AlphaFold in biological research. It’s an exquisite example of how molecular machine learning can be used to understand intricate mechanisms that previously eluded us.
Now, things have gotten even crazier. With more research and refinement, Pauli’s lab published a new preprint last month with a high-confidence model that unifies all known sperm fertilization factors, which they call the sperm protein assembly and receptor-binding key (SPARK) complex.
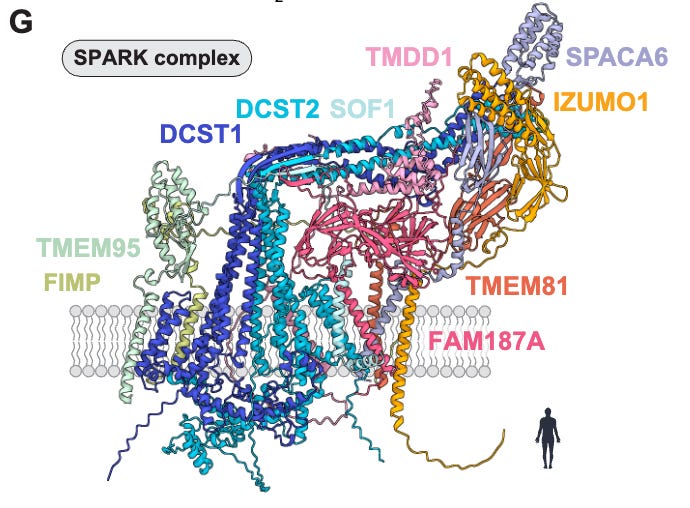
To be clear, this is an AI prediction, not an experimentally solved structure. And that’s the point. It’s an extraordinarily difficult challenge to purify all of these factors and empirically test this prediction. But in an exhaustive array of co-dependency experiments, Pauli’s group showed that each factor is necessary for fertilization—and that they all do seemingly function together. The AI models are behaving like a digital microscope that exceeds the resolution of our experimental measurement tools.
Across CRISPR biology and gene editing, plant evolution, and structural mechanisms of life’s first kiss, it was exciting to see AI tools unlock discoveries in such a wide range of domains.
I’ve just attempted to cover what may have felt like a fairly disorienting amount of science. And that was just a slice of what was covered at the Symposium. There are two reasons for this.
First, the CSHL Symposium is a unique and wonderful conference. The entire format is designed to deliver a non-stop stream of exciting results from some of the top scientists in the world for five days straight. My coverage here was necessarily a lossy compression—including the complete omission of a great set of sessions on AI for neuroscience as well as neuro-inspired AI.
Second, there is simply a lot happening at the intersection of AI and biology right now. Research efforts underway span nearly every scale of biological organization and inquiry. New models are being built and new questions are being asked every day.
Beyond any of the themes we just explored, one of my biggest take home observations from the Symposium was a dramatic change in sentiment. For many years, AI methods in biology were viewed skeptically by most biologists—even computational biologists. Even when certain models started to really work, there was a gradual thawing period.
Ewan Birney, a legendary bioinformatician who played a key role in the Human Genome Project, described his own journey through these phases. At first, he felt like these wacky models with more parameters than data points were basically “voodoo.” Now, he described himself as “Saul on the road to Damascus.” He’s a big believer and his lab is pushing many exciting AI projects forward.
AI is now front and center in biology, and this Symposium was a reflection of that.
The goal for this field is no longer to capture the attention and interest of biologists.
We have that in spades.
The goal is to deliver on the extraordinary amount of enthusiasm and promise.
If we look back in several decades, my bet is that the seeds of this nascent revolution will have been planted by the brilliant scientists who traveled from around the world for this meeting of minds at The Lab—just like the pioneers of the molecular biology revolution that preceded them.
Thanks for reading this winding overview of CSHL’s 90th annual Symposium on Quantitative Biology.
If you don’t want to miss upcoming essays, you should consider subscribing for free to have them delivered to your inbox:
Until next time! 🧬
Sadly, I learned that this tradition was paused during the Covid pandemic and never returned. Another great part of the interview experience was a trip into Manhattan for a Broadway show.
Many of the researchers that laid the foundation for the information sciences also drew inspiration from biology. In fact, Claude Shannon, the father of information theory, wrote his PhD thesis on mathematical population genetics while at CSHL. He was advised to do so by Vannevar Bush, a figure who shaped much of how scientific research came to be funded and organized in the U.S. after World War II.
Peter Koo gave a great talk in the same session on ideas to improve the performance of sequence-to-function models. It may be possible to fine-tune models on experimental perturbation data to better learn regulatory rules, but this will require incorporation of techniques from the field of continual learning. You can read more about these ideas in their recent perspective here.
Anshul Kundaje also gave a great talk on how “lightweight, task-specific supervised models” trained on smaller regions of DNA and less data types can still shine in deciphering complex regulatory mechanisms with high resolution. These models are fast and cheap which can help for downstream model interpretability research.
David Van Valen, an assistant professor at Caltech, briefly highlighted a related project. They have developed techniques to automate the assembly of protein complexes from Cryo-EM data.
Loved it. Recently read "What to make of a life" by Jim Collins and he covers Barbara's work brilliantly so great to see Cold Spring Harbor as so relevant today.
The real question is what kind of science AI helps us do. Faster predictions are impressive, but the more interesting part is whether AI can help scientists ask better questions, connect biological scales, and reduce uncertainty. That feels much bigger than automation.