
What's different? Part three: Scale
Massively parallelizing everything, programmable perturbations, lab automation

Overview
Around the same time that we stagnated in our ability to build big things in the physical world—especially in the West—we got really good at precisely manufacturing small things. Here, I’m talking about semiconductor manufacturing. We developed the ability to precisely engineer circuits on the scale of micrometers, and ultimately nanometers. This enabled the personal computer revolution that changed the world. We now have a global communication network that lets use share our memes and dreams with anybody in the world.
Meanwhile, biology was undergoing its own revolution. We transitioned from macroscopic descriptions of living organisms to molecular descriptions of cells. Some really interesting things happened when the semiconductor revolution and the molecular revolution began to collide. Over a series of posts, I’ve talked about the next-generation DNA Sequencing revolution, and the progress that has been made in DNA Synthesis.
The punch line is that we have developed sophisticated technologies for massively parallelizing DNA sequencing and synthesis. These breakthroughs were made possible by blending molecular biology protocols with tools and engineering techniques from the computer revolution. We can now read and write enormous numbers of DNA sequences simultaneously—opening the door to totally new types of biotechnology.
My core thesis is that we have a new biotechnology stack built around Sequencing, Synthesis, Scale, and Software. In this post I’m going to explore what has enabled the Scale of science and engineering in modern biotech. We’ll look at:
Massively parallelizing everything
Programmable perturbations (CRISPR)
Progress in lab automation
Let’s jump in!
Massively parallelizing everything
Most experiments consist of perturbing a system, and then measuring what happens. In molecular biology and genetics, this process often involves trying to modify genes and their regulatory elements to see how they work.
A concrete example is the reporter gene assay. This type of experiment can be used to figure out what regulatory sequences of DNA are necessary to turn a gene on and off. The core idea is to construct a stretch of DNA that contains both the regulatory element in question, and a gene that can be easily detected when it is expressed.

{kind=link}
Historically, in a molecular biology lab this type of construct would be set up using molecular cloning—where recombinant DNA technology originally developed in the 1970s is used to reshuffle sequences of DNA into a desired order. The core measurement tool would often be a reporter protein such as green fluorescent protein (GFP) which can be visually detected.
Things now happen a bit differently in the post-genomic era. For an experiment, if the perturbation can be done using Synthesis, and the measurement can be done using Sequencing, it becomes possible to massively parallelize the entire workflow. Now, we move from the basic setup of the reporter assay to the massively parallel reporter assay (MPRA).

It is possible to test a large number of different sequences in parallel by synthesizing them in a pool of oligos. Instead of using fluorescence, the readout of an MPRA is measured using sequencing. This is done by taking the ratio of barcode sequences encoded in the oligo pool. If a sequence drives RNA expression, there will be far more RNA copies of the barcode than the original DNA barcode.
This is a really important shift. Human geneticists try to understand how DNA differences lead to differences in traits—ranging from height to the likelihood of developing a disease. One of the big problems is that most genetic variants associated with complex traits don’t directly change the sequences of genes, making it hard to explain what they do. MPRAs have dramatically changed the Scale of experimentally testing these important regulatory sequences.
This is great for human genetics, but it’s also an illustrative example of a broader trend.
If you can develop a way to use a Sequencing/Synthesis approach to tackle a problem, the Scale of your experimental throughput immediately changes. This is why one of the first applications of large-scale DNA synthesis was to parallelize the use of molecular tools such as hairpin RNAs for silencing the expression of genes. For any tool that can fit into this paradigm, you can go from a dozen measurements to thousands of measurements or more.
Another important component of this paradigm is that the list of things that we can measure with Sequencing grows every day. Beyond DNA and RNA, technologies have been developed to measure a wide variety of functional properties in cells. Examples include tools for measuring the physical accessibility of the genome, as well as the 3D conformation of the genome within cells. Sequencing technology development and extension has become a cottage industry in genomics, with creatively named tools like DRUG-seq, Death-seq, and DiMeLo-seq being created to measure new properties using NGS.1
It turns out that this general approach can be used for a lot of problems—even ones that aren’t obvious. One of my favorite examples is how DNA-encoded libraries (DELs) have swept through drug discovery. Originally dreamed up by Richard Lerner and Sydney Brenner, DELs have massively scaled the drug screening process by turning it into a Sequencing/Synthesis problem.

Chemical building blocks are barcoded with tags of DNA, and then mixed and matched in successive rounds of splitting and pooling to create libraries of literally trillions of different compounds in a single tube. This is essentially standard practice in modern drug discovery now, and Nobel laureate Roger Kornberg was quoted saying that he thinks DELs “represent the most innovative and broadly significant advance in chemistry in the past decade or more.”
It’s worth being concrete about what made this leap in Scale possible. As HitGen’s CSO Barry A. Morgan points out, it is “really a tribute to the fundamental developments over the last 30 years in our ability to manipulate and sequence DNA.”
Programmable perturbations (CRISPR)
It is impossible to talk about Scale without talking about CRISPR. Having originally evolved as a form of bacterial immune defense against viruses, the CRISPR-Cas9 system has been adapted for use as a genome editing technology.
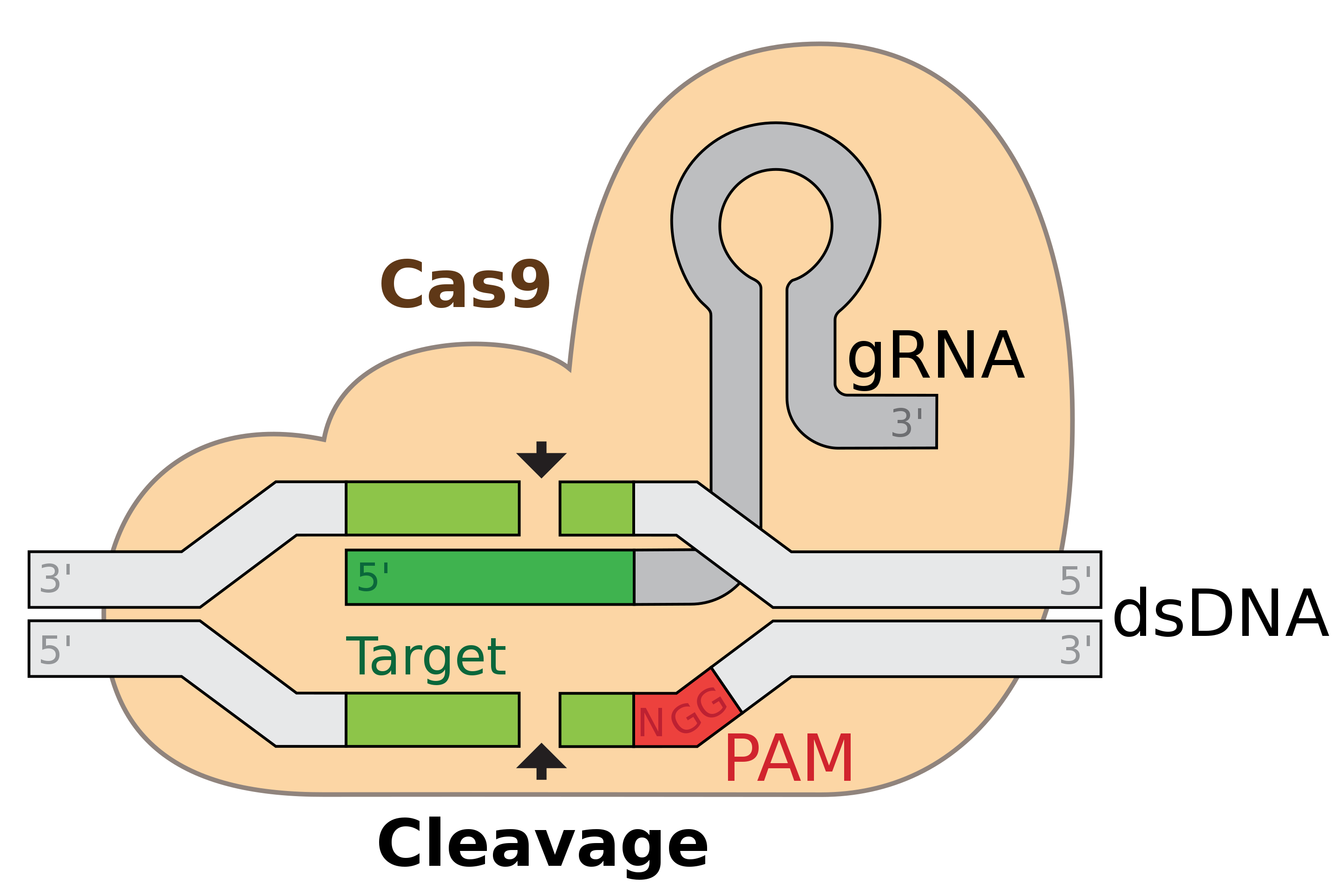
{kind=link}
This diagram shows how a guide RNA (gRNA) sequences is used to target the Cas9 protein to edit double-stranded DNA. One of the most widely used analogies for the CRISPR system is that it is like a programmable pair of molecular scissors. It can be used to target arbitrary sequences by designing different gRNAs. Since the original use for making programmed edits, the CRISPR toolbox has expanded dramatically to include approaches for silencing genes without changing the sequence, and also activating genes.
It’s hard to overstate how transformative this technology has been for the life sciences. Often, conversations between generations of scientists trained before and after the discovery will include comments such as “you probably don’t know about [insert technology/approach], because now you would just use CRISPR.” All of a sudden, we have a general tool for targeting nucleic acid sequences in a programmatic fashion, and it only gets more refined each day.
A huge benefit of CRISPR is that you can plug it right into the Sequencing/Synthesis framework that I’ve been describing. While it can be used with small sets of guide RNAs, it is also possible to design massive oligo libraries of guide RNAs targeting all of the genes in the genome. The impact of the programmed edit/silencing/activation can be measured using Sequencing technology. A technology that combines many of the tools I’ve been describing in this series is called Perturb-seq:
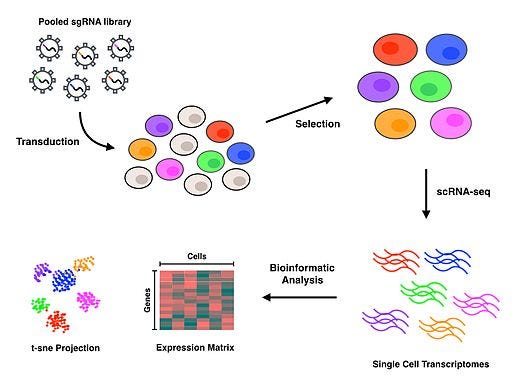
{kind=link}
In this technology, a barcoded library of guide RNAs is introduced into cells that are individually sequenced using the approach I described last week. The barcodes can be used to retrospectively assign which guide RNA ended up in a given cell.
I previously wrote about a study done earlier this year that used Perturb-seq to create a massive genotype-phenotype map. This type of approach essentially attempts to parallelize the fundamental scientific process of perturbing a system and measuring the response, with the goal of “dissecting molecular circuits.”
Outside of accelerating and Scaling experimental science, the direct use of CRISPR for genome editing has obvious consequences for engineering. A robust and programmable editing tool is a big deal for synthetic biology. In fact, one of the major challenges that several companies are trying to tackle is how to rapidly evaluate libraries of edited cells created with massively parallel genome engineering. With editing technology in hand, there is a renewed focus on the design and evaluation bottleneck.
Progress in lab automation
DNA is a beautiful polymer that can store information. It’s the killer enabling technology for life as we know it. Learning how to sequence it, synthesize it, and edit it has had enormous scientific and technological value—and we’ve only just gotten going.
We have also made strides in Scaling biotech outside of using our newfound superpowers of wielding DNA. Lab automation is a big part of this. While I intend to write more about this in the coming year, I’ll categorize three main buckets of lab automation: 1) in-house facilities, 2) in-lab instruments, and 3) cloud-lab providers.
A lot of biology involves precisely transferring small volumes of liquid. While most of molecular biology has been done by individual scientists using pipettes to do this, things are starting to change. One approach to automating experimental work has been to develop in-house facilities at universities and companies. These core centers develop approaches to automating common types of experiments.

Having access to these types of facilities as a young scientist totally changed my conception of what type of Scale was possible for a given experiment—and also impacted how I wanted to spend my time. I got to spend less time cranking out assays and more time doing analysis!
These types of facilities have a few drawbacks. They often lack the flexibility needed to automate specific protocols or one-off experiments. They can also be difficult to book, and delay progress with wait times as a shared resource. For these situations, in-lab instruments can be a great solution. One of my favorite examples is the Opentrons OT-2 which is a bench-top automation system that can be programmed using a Python API or an app. This type of solution Scales experimental workflows in a decentralized fashion.
A more long-term dream is to have access to experiments-as-a-service, just like a software engineer would consume Amazon Web Services. In this cloud-lab provider model, companies like Strateos and Emerald Cloud Lab are aiming to build out modular lab automation platforms—and to make them available remotely via an API or application. There are major engineering and cultural challenges that still need to be overcome before this paradigm can reach large-scale adoption.
Next time: Software
Massively parallel Sequencing and Synthesis have changed biology. They can be combined in creative ways to massively parallelize everything. With new programmable molecular tools like CRISPR, we can also dramatically Scale scientific perturbations and genome engineering. This has revolutionized biotech, before even accounting for the progress being made in lab automation and robotics.
All of this new tooling and data has generated massive bottlenecks for design and analysis. The final post in this series will provide an overview of the types of Software and models that are being developed to tackle these challenges.
The goal of this series is to share a broad thesis about the foundational technologies that are powering the modern biotech revolution. My hope is that the Sequencing, Synthesis, Scale, and Software mental model will provide a useful reference frame for better understanding the cutting-edge science and startups that I will write about in this newsletter. 🧬
After DRUG-seq, I’m anxiously waiting for SEX-seq and RoCk-n-RoLL-seq.