
Techniques for DNA databases
A new PCR technique for oligonucleotide retrieval

Overview
Scientists have a tendency to use metaphors about the most complex mechanical systems of their time to reason about natural systems. A classic historical example is the belief in a Clockwork Universe around the time of the birth of Newtonian physics. As concise mathematical laws made more and more of the physical world predictable, scientists and philosophers envisioned the universe as a perfect and logical system, with the laws meshing together like the gears on a watch.
Given this history, it is fair to be skeptical about the large number of computer metaphors cropping up in every field of science as we live through the Information Age. For example, many scientists don’t know what to make of MIT physicist Seth Lloyd’s argument that we should think of the world as a giant quantum computer. In the same vein, computer metaphors are often met with skepticism by biologists. However, as I’ve written about before, there are times in modern biology where the computation being talked about is no longer metaphorical. One of the most literal examples can be found in the field of DNA data storage.
If you crack open any standard high school or college biology textbook written since the molecular revolution, you will find countless examples of phrases about “DNA encoding information” or the “flow of genetic information” that takes place in the central dogma. I found all of this frustratingly vague, and it was one of the major reasons that I decided to spend a substantial amount of time studying computer science. It was only when I learned more about Claude Shannon’s information theory and the world of bits that this started to make sense, and I realized that information in biology is not a metaphor.
Bases of DNA literally encode discrete units of information in the form of a molecular quaternary code. Because of this fact, it has been demonstrated time and time again that you can convert digital information into this code, encode it in physical DNA, and then accurately retrieve what you encoded. This general workflow is the foundation for the field of DNA data storage, which seeks to optimize this entire process and turn it into a competitive alternative to digital databases. How could this ever be possible? Well, DNA is the only highly stable nanoscale information storage technology that we know of. Conceptually, an exabyte of data could fit in the palm of your hand. This could help alleviate the large space and energy costs of maintaining enormous digital databases as we continue to collect more and more data as a species.
One of the research groups at the forefront of making this technology a reality is the University of Washington Molecular Information Systems Lab (MISL), which is a joint effort between the UW and Microsoft Research. Today, I’m going to be highlighting a new preprint from the group entitled “A Combinatorial PCR Method for Efficient, Selective Oligo Retrieval from Complex Oligo Pools”. This work introduces a clever new lab technique that may have applications in DNA data storage as well as other areas in biotechnology.
Key Advances
One of the absolute pillars of modern biotechnology is array-based oligonucleotide (oligo) synthesis. This is a technology where thousands of short sequences of DNA are simultaneously synthesized on a chip for further use. The exact composition of the oligos is completely programmable, opening the door to a huge variety of applications such as gene synthesis, designing CRISPR libraries for gene editing, and new oligo-based advancing imaging techniques1. Incredibly, this technology has been commoditized, and it is possible to order a pool of oligos for use from a company such as Twist Bioscience.
As I’ve mentioned, there is a fundamental workflow for storing digital information in DNA:

With an established encoding, DNA representing the information is synthesized, typically using a very large oligo array. With large arrays, a technical question arises: “as thousands to millions of oligos are made together in a single oligo pool, how can we selectively retrieve one or more specific oligos (e.g., a gene fragment or a data file encoded in DNA)?”
The traditional approach for retrieving sequences is to sandwich all of the oligo sequences with a unique forward PCR primer at the beginning and a unique reverse PCR primer at the end in order to make the sequence “addressable” by a round of PCR amplification.2 This strategy works but doesn’t scale, because the number of unique primers required grows linearly with the number of sequences that need to be addressable in the array, which is costly.
This paper looks to improve on a recent hierarchical PCR scheme aimed to mitigate this problem that works by using a “hierarchical addressing method with a universal reverse primer and two nested forward primers” which helped with scaling, but introduced protocol complexity and reduced retrieval fidelity.
I love the simplicity and effectiveness of the technique introduced in this paper. They propose to use a straightforward combinatorial strategy, using all possible combinations of forward and reverse primers:

In this way, “ten total primer sequences (five forward and five reverse primers) can uniquely identify 25 files, and the target file is simply accessed with standard PCR.” This makes the strategy easy to understand and to execute.
Results
In order to evaluate this approach, the authors designed a small oligo array with 9 forward and 9 reverse primers, encoding 81 unique addressable sequences. In order to approximate a complex library, the sequences being encoded were random strings of DNA. They performed PCR amplification to retrieve the encoded sequences, and sequenced them to test the accuracy.
Interpreting the results is straightforward, because it is a question of accurate lookup from a database. Does the sequence match what I was supposed to retrieve? The combinatorial PCR strategy performed well on this front:
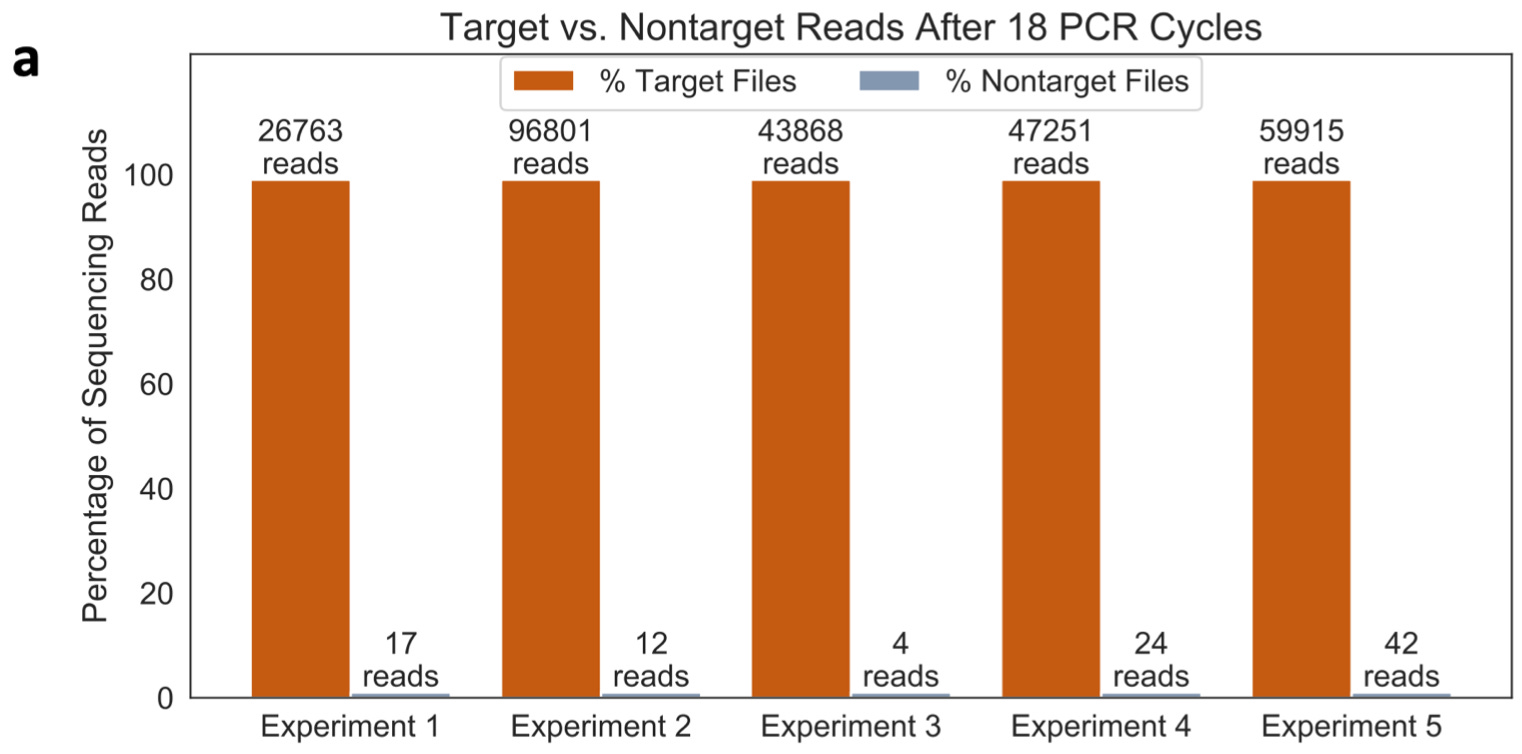
Empirically, it seems like the combinatorial PCR strategy enables a very selective lookup. A benefit of this is that it requires less sequencing depth, which makes it more cost effective.
One shortcoming of this demonstration is that it is a much smaller library than would be used for a DNA database in practice. In order to mitigate this concern, the authors used simulations to evaluate the scaling potential of the strategy, and the results were promising. I’ll leave that set of results for readers who want to go deeper on this paper.
Final Thoughts
Metaphors about computation are increasingly common in biology, and are often met with a range of enthusiasm. However, increasingly computation is not a metaphor in biotechnology, as engineers work to program cells and determine the storage capacity of DNA. There are a number of interesting technical problems to work out in order to make technologies such as DNA data storage viable, but they offer the promise of nearly infinitely scalable cold storage of digital information.
The authors of this paper described and validated a simple and effective PCR strategy for scaling the ability to selectively retrieve sequences from oligo pools. It will require more research and tools like this for the field of DNA data storage to become accurate and scalable enough to outcompete digital databases for longterm storage. Speculating a bit, I wonder if genome scientists will actually become the first major adopters of DNA storage. The field may become the largest data generator on the planet, but it has the best infrastructure and knowledge to adopt DNA data storage technologies in-house. I’ll be curious to see if this starts to happen as the technology matures.3
Thanks for reading this highlight of “A Combinatorial PCR Method for Efficient, Selective Oligo Retrieval from Complex Oligo Pools”. If you’ve enjoyed reading this and would be interested in getting a highlight of a new open-access paper in your inbox each Sunday, you should consider subscribing:
That’s all for this week, have a great Sunday! 🧬
I spent two years working on the latter. If you’re interested in this field, check out the paper describing Oligopaints, or technologies such as MERFISH or ORCA.
For technically curious readers coming from other disciplines who are interested in learning about biotechnology, reviewing PCR is really worthwhile. It will come up everywhere.
Obviously, the other business model here is to offer this as an abstracted service that is equivalent in performance to digital databases but cost-competitive.