
Simulating eco-evolution
A new simulation engine for modeling the Earth's biodiversity


Overview
This week, I’m highlighting a new publication that is pretty far outside of my typical research/reading area of genomics, machine learning, and bioinformatics. The paper is “gen3sis: A general engine for eco-evolutionary simulations of the processes that shape Earth’s biodiversity” which was led by Oskar Hagen while in the Landscape Ecology Group at ETH Zürich directed by Loïc Pellissier.
In general, I try to read work from a broad range of fields because I think that there is tremendous room for the cross-pollination of useful ideas and techniques when trying to understand how people tackle problems that are different from what I work on each day. There is also just so much exciting work going on in so many areas that it keeps things fun.
While this paper isn’t in my field or in a journal that I consistently read1, there are actually many core methodological similarities. I think that this is reflective of some of the ways that science has evolved in the late 20th and early 21st century to become a largely data-intensive endeavor. One of the visionaries of this transition was Jim Gray who felt that we were entering a Fourth Paradigm of science.
According to Gray, the Fourth Paradigm of science is data-intensive science, which builds on and integrates the preceding paradigms of experimental, theoretical, and computational science. In the time following his predictions, there has been a considerable amount of evidence indicating that he was on to something.
Take for example, the UW eScience Institute, which was located across the street from the department where I worked. The institute describes its mission in the following way:
The eScience Institute empowers researchers and students in all fields to answer fundamental questions through the use of large, complex, and noisy data. As the hub of data-intensive discovery on campus, we lead a community of innovators in the techniques, technologies, and best practices of data science and the fields that depend on them.
This hub ultimately brought together students and researchers from the biological, environmental, physical, and social sciences, who all increasingly relied on the same tools for their work. It didn’t matter if you were studying black holes, genome evolution, or ocean temperature changes, you probably were writing Python code to wrangle your data in a Jupyter notebook or doing modeling with R in RStudio.
I think that this fundamental shift in how science is conducted is really noteworthy, and establishes something of a lingua franca that provides the necessary fabric for interdisciplinary work and communication.
To put this concretely, even though I’m currently working on genome browsers and data visualization, as an R package developer, I can comfortably derive insights from studying gen3sis, which is the R package for eco-evolutionary simulation introduced in this work. I found the interface design of the package to be really interesting, as well as the domain area that it was built for.
With that preamble out of the way, let’s take a look at this eco-evolutionary simulation engine!
Key Advances
The field that gen3sis was built for is concerned with answering one of the most fundamental questions about evolution and life on Earth: what are the origins of the biodiversity that we see? Here is how the authors describe this problem:
Species richness varies across regions, such as continents, and along spatial and environmental gradients, such as latitude. These well-known patterns, derived from the observed multitude of life forms on Earth, have intrigued naturalists for centuries and stimulated the formulation of numerous hypotheses to explain their origin.
Clearly, this is an extraordinarily complex process that unfolds over enormous timescales. This system is parameterized by a wide variety of different interacting processes and feedback loops. In a somewhat similar predicament, population geneticists have adopted a paradigm of establishing explanatory models, simulating them, and comparing the simulation results to observed data and patterns.2
This type of framework was proposed in this field a decade ago by a group of researchers calling for a “general simulation model for macroecology and macroevolution.”3 In the time since then, the authors argue that there has been a surge in research using simulations, but that no framework general enough to explore and compare all of the relevant possible models has emerged. This is where gen3sis enters the scene.
The interface of the simulation framework can be explored to understand what factors are considered for understanding the emergent patterns of biodiversity:

There are two input objects into the simulation: landscape and configuration. The engine then runs simulations that generate distribution, phylogenetic, and ecological data, whose accuracy can be evaluated against empirical data.
These top-level input objects can each be tuned and controlled with great detail. In this way, the design attempts to successfully support a really broad range of simulations and models. For example, the landscape “may be simplified into a single geographic axis for theoretical experiments, or it may consider realistic configurations aimed at reproducing real local or global landscapes.”
The configuration object is composed out of 6 functions, 4 of which represent the most core processes that are being modeled: speciation, dispersal, evolution, and ecology.4 The interface for each function appears to provide a lot of flexibility in how each of these processes is parameterized.
I think this is a great example of interface design for scientific software. The inputs are composed together nicely, and model how a scientist in the field would think about this problem. The actual engine for computation is abstracted away (with runtime-critical functions written in C++ for speed), and the outputs represent what somebody would want to evaluate against empirical data.
Results
In addition to the introduction of the new engine, this paper presents an interesting case study to demonstrate how it works in practice and to evaluate its accuracy. The case study is a model of the formation of the Latitudinal Diversity Gradient (LDG) over the Cenozoic era. The LDG is the term for the pattern of species diversity where there is a great abundance of species near the equator, and a gradient of declining abundance the further you move away from the equator:
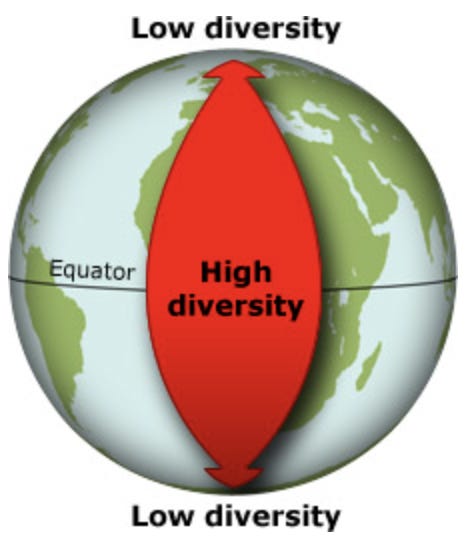
The Cenozoic era is the geological time period that ranges from 65 million years ago until the present day. This period was chosen because this is when the “modern LDG is expected to have formed.” For their simulation they chose to test 2 representative landscapes, and 5 models representing different hypotheses for the emergence of this pattern. I found the results to be pretty impressive:

From this figure, you can see how detailed the underlying landscape model is, where the landscape input (figure 4a) represents the shifts in continents over time (extremely cool). It also looks like the simulation engine is powerful enough to represent complex processes like the LDG to sufficiently correspond with empirical data.
The best performing model (M5 in L1) was the one that “imposed an energetic carrying capacity.”5 There are a lot more metrics for how different models performed in the paper.
Another set of results worth checking out are 4 really cool animations of the landscapes and biodiversity patterns that are available as MP4s in the Supporting Information section. A player for the animations is embedded directly in the page at the bottom of the article, which I think is a step in the direction for leveraging the power of the Web to do a better job of sharing and communicating science. Good job PLOS!
Final Thoughts
Understanding the dynamics of biodiversity is a truly fundamental scientific question. It also seems like having accurate quantitative underpinnings for these models will be increasingly important as we try to predict and understand the ramifications of global climate change. Perhaps these computer models could even be used to evaluate and prioritize future engineering and technology projects aimed at mitigating the profound loss of biodiversity that we are currently living through.
I really enjoyed learning about this field from the perspective of a software engineer, thinking about what inputs are required to flexibly represent all of the processes involved in such a complex and large system. If you are like me and this work is outside of your typical reading, I hope you enjoyed this excursion with me! I think there are cool ideas here that could also be applied to other dynamic and time-based processes, such as gene regulation, cancer biology, and longevity research.
Thanks for reading this highlight of “gen3sis: A general engine for eco-evolutionary simulations of the processes that shape Earth’s biodiversity”. If you’ve enjoyed reading this and would be interested in getting a highlight of a new open-access paper in your inbox each Sunday, you should consider subscribing:
That’s all for this week, have a great Sunday! 🧬
PLOS Computational Biology and PLOS Genetics are my two main PLOS reads.
If this sounds interesting, I recently wrote a highlight of a great preprint combining population genetic simulations and machine learning that can be found here.
The work cited here is “Patterns and causes of species richness: a general simulation model for macroecology”
Table 1 in the paper breaks these down into more detail in a very accessible way.
What this means in practice: “In the implementation of the ecological limits, the ecology function included a carrying capacity k of each site that scaled with area energy (i.e., temperature and aridity).”